排列:
(A、B、C、D)的全排列为
1、A后面跟(B、C、D)的全排列
2、B后面跟(A、C、D)的全排列
3、C后面跟(A、B、D)的全排列
4、D后面跟(A、B、C)的全排列
void permutation(int a[], int m, int k) { if (k>m) { for (int i = 0; i <= m; i++) cout << a[i] << " "; cout << endl; } else { for (int i = k; i <= m; i++) { swap(a[k], a[i]); permutation(a, m, k + 1); swap(a[k], a[i]); } } } void perm(int *a, int n) { permutation(a, n - 1, 0); } int main() { int a[] = { 1, 2, 3, 4, 5 }; int len = sizeof(a) / sizeof(a[0]); perm(a, len); }
或者:
#include <iostream> using namespace std; template<typename T> void permutation(T array[], int begin, int end) { int i; if(begin == end){ for(i = 0; i <= end; ++i){ cout<<array[i]<<" "; } cout<<endl; return; } else { //for循环遍历该排列中第一个位置的所有可能情况 for(i = begin; i <= end; ++i) { swap(array[i], array[begin]); permutation(array, begin + 1, end); swap(array[i], array[begin]); } } } int main(int argc, char **argv) { int a[4] = {1, 2, 3, 4}; permutation(a, 0, sizeof(a) / sizeof(int) - 1); return 0; }
非递归全排列算法,即按字典序排列算法。
基本思想是:
1.对初始队列进行排序,找到所有排列中最小的一个排列Pmin。
2.找到刚刚好比Pmin大比其它都小的排列P(min+1)。
3.循环执行第二步,直到找到一个最大的排列,算法结束。
如排列ABCDE,这是所有排列中最小的一个排列,刚好比ABCDE大的排列是:ABCED。
算法如下:
给定已知序列P = A1A2A3…..An
对P按字典排序,得到P的一个最小排列Pmin = A1A2A3….An ,满足Ai > A(i-1) (1 < i <= n)
从Pmin开始,找到刚好比Pmin大的一个排列P(min+1),再找到刚好比P(min+1)大的一个排列,如此重复。
1.从后向前(即从An->A1),找到第一对为升序的相邻元素,即Ai < A(i+1)。
若找不到这样的Ai,说明已经找到最后一个全排列,可以返回了。
2.从后向前,找到第一个比Ai大的数Aj,交换Ai和Aj。
3.将排列中A(i+1)A(i+2)….An这个序列的数逆序倒置,即An…..A(i+2)A(i+1)。因为由前面第1、2可以得知,A(i+1)>=A(i+2)>=…..>=An,这为一个升序序列,应将该序列逆序倒置,所得到的新排列才刚刚好比上个排列大。
4.重复步骤1-3,直到返回。
更详细看:
全排列的非递归就是由后向前找替换数和替换点,然后由后向前找第一个比替换数大的数与替换数交换,最后颠倒替换点后的所有数据。
http://blog.csdn.net/nanjunxiao/article/details/9081487 非常好:
http://blog.csdn.net/morewindows/article/details/7370155/
这个算法是C++ STL算法next_permutation的思想。
/********************************************************************** * Compiler: GCC * Last Update: Mon 07 May 2012 07:08:58 PM CST * File Name: 1.cpp * Description: ************************************************************************/ #include <iostream> #include <cstring> using namespace std; //交换数组a中下标为i和j的两个元素的值 void swap(int *a,int i,int j) { a[i]^=a[j]; a[j]^=a[i]; a[i]^=a[j]; } //将数组a中的下标i到下标j之间的所有元素逆序倒置 void reverse(int a[],int i,int j) { for(; i<j; ++i,--j) { swap(a,i,j); } } void print(int a[],int length) { for(int i=0; i<length; ++i) cout<<a[i]<<" "; cout<<endl; } //求取全排列,打印结果 void combination(int a[],int length) { if(length<2) return; bool end=false; while(true) { print(a,length); int i,j; //找到不符合趋势的元素的下标i for(i=length-2; i>=0; --i) { if(a[i]<a[i+1]) break; else if(i==0) return; } for(j=length-1; j>i; --j) { if(a[j]>a[i]) break; } swap(a,i,j); reverse(a,i+1,length-1); } } int main(int argc, char **argv) { int a[4] = {1, 2, 3, 4}; combination(a, sizeof(a) / sizeof(int)); return 0; }
用STL实现:
STL有一个函数next_permutation(),它的作用是如果对于一个序列,存在按照字典排序后这个排列的下一个排列,那么就返回true且产生这个排列,否则返回false。
void stl_perm3(int a[], int n) { sort(a, a + n); do{ for (int i = 0; i < n; i++) cout << a[i] << " "; cout << endl; } while (next_permutation(a, a + n)); }
转自:http://blog.csdn.net/e3399/article/details/7543861
求组合数(C(n,r)
在循环设计中,对n=5(r=3)的实例,每个组合中的数据从小到大排列或从大到小排列一样可以设计出相应的算法。但用递归思想进行设计时,每个组合中的数据从大到小排列确是必须的,因为递归算法设计是要找出大规模问题与小规模问题之间的关系。 当n=5,r=3时,从大到小排列的组合数为: 5 4 3 5 4 2 4 4 1 5 3 2 。。。 3 2 1 共10个。 分析以上数据,组合数规律如下: 1.首先固定第一个数,其后就是求解n=4,r=2的组合数,共6个组合 2.其次固定第一个数4,其后就是求解n=3,r=2的组合数。共3个 3.最后固定第一个数3,其后就是求解n=2,r=2的组合数,共1个。
递归方法:
void
comb(
int
m,
int
k)
{
int
i,j;
for
(i=m;i>=k;i–)
{
a[k]=i;
if
(k>1)
{
comb(i-1,k-1);
}
else
{
for
(j=a[0];j>0;j–)
//a[0]存储的是原素个数
{
cout<<a[j]<<ends;
}
cout<<endl;
}
}
}
int main() { int n,r; cin>>n>>r; a[0]=r; comb(n,r); cout<<count<<endl; }

另外的:
算法说明:从n个数中选m个数,可以分解为以下两步(1)首先从n个数中选取编号最大的数,然后在剩下的n-1个数中选取m-1个数,直到从n-(m-1)个数中选取1个数为止。对于OIF计算来说,m=3。(2)从n个数中选取编号次小的一个数,继续执行第(1)步,直到当前可选编号最大的数为m。下面该递归算法的C++实现,在VC 6.0里编译通过。
/*求从a[n]中选取m个数的可能组合。数组a[n]表示候选集,即影像的波段数;b[m]用来存储当前组合中的某个元素,这里存储的是这个元素在a[]中的下标;常量M表示满足条件的一个组合中元素的个数,M=m,M只用来输出结果*/
#include <iostream.h>
void Combine(int a[], int n ,int m, int b[], const int M);
int main()
{
//从N个数中选M个数,N=6,M=3
const int N = 6;
const int M = 3;
int a[N];
int b[M]; //用来存储当前组合中元素(这里存储是元素下标)
for (int i = 0; i < N; i++)
a[i] = i+1;
Combine(a, N, M, b, M);
return 0;
}
void Combine(int a[], int n ,int m, int b[], const int M)
{
for (int i = n; i >= m; i–)
{
b[m-1] = i -1; //选取候选集a[]中最大的一个数,记录其下标
if (m > 1)
Combine(a, i-1, m-1, b, M); //从n-1中再选m-1个元素
else //1==m,没有元素可选,一个组合已经完成,输出
{
for (int j = M-1; j >= 0; j–)
cout<<a[b[j]];
cout<<endl;
}
}
}
回溯法求解:
采用回溯法找问题的解,将找到的组合以从小到大顺序存于a[0],a[1],…,a[r-1]
中,组合的元素满足以下性质:
(1) a[i+1]>a[i],后一个数字比前一个大;
(2) a[i]-i<=n-r+1。
算法具体实现如下(以求5个自然数中3个数的组合):

如图所示:为一个求组合问题的解空间,以深度优先的方式对该树进行遍历,到叶节点是输出一个解,当整棵树遍历完成之后就可以得到问题的所有解:
算法的具体实现如下:、
#include <stdio.h> #include <stdlib.h> #include <malloc.h> int n;//自然数的个数 int r; int *com;//存放一个生成的组合用于输出 void backtrack(int k); void output(); int main(int argc,char **argv) { printf("请输入自然数的个数n和组合个数r\n"); scanf("%d%d",&n,&r); if (r>n) { printf("输入数据错误!"); return 0; } com=(int*)malloc(r*sizeof(int)); com[0]=1;//组合数是从1开始的 backtrack(0); return 1; } void backtrack(int k) { int i=0; int j=0; if(k>=r) { output();//到达叶节点输出结果 return; }else{ for(j=1;j<=n-com[k]+1;j++)//遍历一个节点下的所有节点 { com[k+1]=com[k]+j; backtrack(k+1);//前进 ,递归 com[k]++; backtrack(k);//回溯 } } } void output() { int i=0; for (i=0;i<r;i++) { printf("%d ",com[i]); } printf("\n"); }
参考:http://www.cnblogs.com/black-pearl/archive/2013/05/10/3071721.html
为什么是
for(int j=1;j<=n-comb[k]+1;j++)
不是j<=n-comb[k];
更多:http://hi.baidu.com/mafia1974/item/96f7f79ea6595d82581461bf
网上面看到的解法:
典型的排列组合问题,首选回溯法,为了简化问题,我们将a中n个元素值分别设置为1-n
#include <iostream> #include <vector> using namespace std; int array[5] = {0,1,2,3,4}; vector<int> obj; #define NULLELEMENT -1 //组合问题 void selectC(int depth) { if (depth == 3) { for (int i = 0; i < obj.size(); ++i) { cout << obj[i] << "\t"; } cout << endl; return; } for (int i = 0; i < 5; ++i) { if (obj.size() > 0 && i <= obj[obj.size() -1]) continue; obj.push_back(array[i]); selectC(depth+1); obj.pop_back(); } } //排列组合 void selectA(int depth) { if (depth == 3) { for (int i = 0; i < obj.size(); ++i) { cout << obj[i] << "\t"; } cout << endl; return; } for (int i = 0; i < 5; ++i) { if (array[i] == NULLELEMENT) continue; obj.push_back(i); array[i] = NULLELEMENT; selectA(depth+1); array[i] = i; obj.pop_back(); } } int main() { selectA(0); selectC(0); return 0; }
—————
变态组合数C(n,m)求解
问题:求解组合数C(n,m),即从n个相同物品中取出m个的方案数,由于结果可能非常大,对结果模10007即可。
方案一 暴力求解,C(n,m)=n*(n-1)*…*(n-m+1)/m! int Combination(int n, int m) { const int M = 10007; int ans = 1; for(int i=n; i>=(n-m+1); –i) ans *= i; while(m) ans /= m–; return ans % M; } 这种方案的缺陷是,在计算过程中很快ans就溢出了,一般情况下,n不能超过12。补救办法之一是将先乘后除改为交叉地进行乘除,先除能整除的,但也只能满足n稍微增大的情况,n最多只能满足两位数。补救办法之二是换用高精度运算,这样结果不会有问题,只是需要实现大数相乘、相除和取模等运算,实现起来比较麻烦,时间复杂度为O(n)。
方案二 打表,
C(n,m)=C(n-1,m-1)+C(n-1,m) 由于组合数满足以上性质,可以预先生成所有用到的组合数,使用时,直接查找即可。生成的复杂度为O(n^2),查询复杂度为O(1)。较方案一而言,支持的数量级大有提升,在1秒内,基本能处理10000以内的组合数。算法的预处理时间较长,另外空间花费较大,都是平方级的,优点是实现简单,查询时间快。 const int M = 10007; const int MAXN = 1000; int C[MAXN+1][MAXN+1]; void Initial() { int i,j; for(i=0; i<=MAXN; ++i) { C[0][i] = 0; C[i][0] = 1; } for(i=1; i<=MAXN; ++i) { for(j=1; j<=MAXN; ++j) C[i][j] = (C[i-1][j] + C[i-1][j-1]) % M; } } int Combination(int n, int m) { return C[n][m]; }
方案三 质因数分解,C(n,m)=n!/(m!*(n-m)!),设n!分解因式后,质因数p的次数为a;对应地m!分解后p的次数为b;(n-m)!分解后p的次数为c;则C(n,m)分解后,p的次数为a-b-c。计算出所有质因子的次数,它们的积即为答案,即C(n,m)=p1
a1-b1-c1p2
a2-b2-c2…pk
ak-bk-ck。n!分解后p的次数为:n/p+n/p
2+…+n/p
k。 算法的时间复杂度比前两种方案都低,基本上跟n以内的素数个数呈线性关系,而素数个数通常比n都小几个数量级,例如100万以内的素数不到8万个。用筛法生成素数的时间接近线性。该方案1秒钟能计算 1kw数量级的组合数。如果要计算更大,内存和时间消耗都比较大。 //用筛法生成素数 const int MAXN = 1000000; bool arr[MAXN+1] = {false}; vector<int> produce_prim_number() { vector<int> prim; prim.push_back(2); int i,j; for(i=3; i*i<=MAXN; i+=2) { if(!arr[i]) { prim.push_back(i); for(j=i*i; j<=MAXN; j+=i) arr[j] = true; } } while(i<=MAXN) { if(!arr[i]) prim.push_back(i); i+=2; } return prim; } //计算n!中素因子p的指数 int Cal(int x, int p) { int ans = 0; long long rec = p; while(x>=rec) { ans += x/rec; rec *= p; } return ans; } //计算n的k次方对M取模,二分法 int Pow(long long n, int k, int M) { long long ans = 1; while(k) { if(k&1) { ans = (ans * n) % M; } n = (n * n) % M; k >>= 1; } return ans; } //计算C(n,m) int Combination(int n, int m) { const int M = 10007; vector<int> prim = produce_prim_number(); long long ans = 1; int num; for(int i=0; i<prim.size() && prim[i]<=n; ++i) { num = Cal(n, prim[i]) – Cal(m, prim[i]) – Cal(n-m, prim[i]); ans = (ans * Pow(prim[i], num, M)) % M; } return ans; }
方案四 Lucas定理,设p是一个素数(题目中要求取模的数也是素数),将n,m均转化为p进制数,表示如下:
 满足下式:
满足下式:
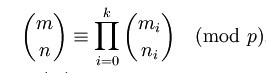 即C(n,m)模p等于p进制数上各位的C(ni,mi)模p的乘积。利用该定理,可以将计算较大的C(n,m)转化成计算各个较小的C(ni,mi)。 该方案能支持整型范围内所有数的组合数计算,甚至支持64位整数,注意中途溢出处理。该算法的时间复杂度跟n几乎不相关了,可以认为算法复杂度在常数和对数之间。 #include <stdio.h> const int M = 10007; int ff[M+5]; //打表,记录n!,避免重复计算 //求最大公因数 int gcd(int a,int b) { if(b==0) return a; else return gcd(b,a%b); } //解线性同余方程,扩展欧几里德定理 int x,y; void Extended_gcd(int a,int b) { if(b==0) { x=1; y=0; } else { Extended_gcd(b,a%b); long t=x; x=y; y=t-(a/b)*y; } } //计算不大的C(n,m) int C(int a,int b) { if(b>a) return 0; b=(ff[a-b]*ff[b])%M; a=ff[a]; int c=gcd(a,b); a/=c; b/=c; Extended_gcd(b,M); x=(x+M)%M; x=(x*a)%M; return x; } //Lucas定理 int Combination(int n, int m) { int ans=1; int a,b; while(m||n) { a=n%M; b=m%M; n/=M; m/=M; ans=(ans*C(a,b))%M; } return ans; } int main(void) { int i,m,n; ff[0]=1; for(i=1;i<=M;i++) //预计算n! ff[i]=(ff[i-1]*i)%M; scanf(“%d%d”,&n, &m); printf(“%d\n”,func(n,m)); return 0; }
即C(n,m)模p等于p进制数上各位的C(ni,mi)模p的乘积。利用该定理,可以将计算较大的C(n,m)转化成计算各个较小的C(ni,mi)。 该方案能支持整型范围内所有数的组合数计算,甚至支持64位整数,注意中途溢出处理。该算法的时间复杂度跟n几乎不相关了,可以认为算法复杂度在常数和对数之间。 #include <stdio.h> const int M = 10007; int ff[M+5]; //打表,记录n!,避免重复计算 //求最大公因数 int gcd(int a,int b) { if(b==0) return a; else return gcd(b,a%b); } //解线性同余方程,扩展欧几里德定理 int x,y; void Extended_gcd(int a,int b) { if(b==0) { x=1; y=0; } else { Extended_gcd(b,a%b); long t=x; x=y; y=t-(a/b)*y; } } //计算不大的C(n,m) int C(int a,int b) { if(b>a) return 0; b=(ff[a-b]*ff[b])%M; a=ff[a]; int c=gcd(a,b); a/=c; b/=c; Extended_gcd(b,M); x=(x+M)%M; x=(x*a)%M; return x; } //Lucas定理 int Combination(int n, int m) { int ans=1; int a,b; while(m||n) { a=n%M; b=m%M; n/=M; m/=M; ans=(ans*C(a,b))%M; } return ans; } int main(void) { int i,m,n; ff[0]=1; for(i=1;i<=M;i++) //预计算n! ff[i]=(ff[i-1]*i)%M; scanf(“%d%d”,&n, &m); printf(“%d\n”,func(n,m)); return 0; }