转自:http://zengzhaozheng.blog.51cto.com/8219051/1557054
一、概述
这2个月为公司数据挖掘系统做一些根据用户标签情况对用户的相似度进行评估,其中涉及一些推荐算法知识,在这段时间研究了一遍《推荐算法实践》和《Mahout in action》,在这里主要是根据这两本书的一些思想和自己的一些理解对分布式基于ItemBase的推荐算法进行实现。其中分两部分,第一部分是根据共现矩阵的方式来简单的推算出用户的推荐项,第二部分则是通过传统的相似度矩阵的方法来实践ItemBase推荐算法。这篇blog主要记录第一部分的内容,并且利用MapReduce进行实现,下一篇blog则是记录第二部分的内容和实现。
二、算法原理
协同推荐算法,作为众多推荐算法中的一种已经被广泛的应用。其主要分为2种,第一种就是基于用户的协同过滤,第二种就是基于物品的协同过滤。
所谓的itemBase推荐算法简单直白的描述就是:用户A喜欢物品X1,用户B喜欢物品X2,如果X1和X2相似则,将A之前喜欢过的物品推荐给B,或者B之前喜欢过的物品推荐给A。这种算法是完全依赖于用户的历史喜欢物品的;所谓的UserBase推荐算法直白地说就是:用户A喜欢物品X1,用户B喜欢物品X2,如果用户A和用户B相似则将物品X1推荐给用户B,将物品X2推荐给用户A。简单的示意图:


至于选择哪种要看自己的实际情况,如果用户量比物品种类多得多那么就采用ItemBase的协同过滤推荐算法,如果是用户量比物品种类少的多则采用UserBase的协同顾虑推荐算,这样选择的一个原因是为了让物品的相似度矩阵或者用户相似度矩阵或者共现矩阵的规模最小化。
三、数据建模
基本的算法上面已经大概说了一下,对于算法来说,对数据建模使之运用在算法之上是重点也是难点。这小节主要根据自己相关项目的经验和《推荐引擎实践》的一些观点来讨论一些。分开2部分说,一是根据共现矩阵推荐、而是根据相似度算法进行推荐。
(1)共现矩阵方式:
第一步:转换成用户向量
1[102:0.1,103:0.2,104:0.3]:表示用户1喜欢的物品列表,以及他们对应的喜好评分。
2[101:0.1,102:0.7,105:0.9]:表示用户2喜欢的物品列表,以及他们对应的喜好评分。
3[102:0.1,103:0.7,104:0.2]:表示用户3喜欢的物品列表,以及他们对应的喜好评分。
第二步:计算共现矩阵
简单地说就是将同时喜欢物品x1和x2的用户数组成矩阵。

第三步:
生成用户对物品的评分矩阵

第四步:物品共现矩阵和用户对物品的评分矩阵相乘得到推荐结果
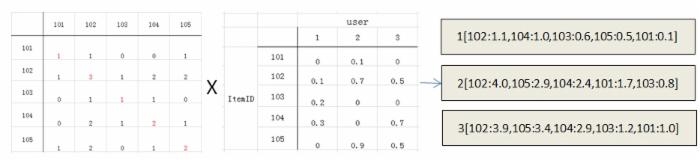
举个例子计算用户1的推荐列表过程:
用户1对物品101的总评分计算:
1*0+1*0.1+0*0.2+0*0.3+1*0=0.1
用户1对物品102的总评分计算:
1*0+3*0.1+1*0.2+2*0.3+2*0=1.1
用户1对物品103的总评分计算:
0*0+1*0.1+1*0.2+1*0.3+0*0=0.6
用户1对物品104的总评分计算:
0*0+2*0.1+1*0.2+2*0.3+1*0=1.0
用户1对物品105的总评分计算:
1*0+2*0.1+0*0.2+1*0.3+2*0=0.5
从而得到用户1的推荐列表为1[101:0.1,102:1.1,103:0.6,104:1.0,105:0.5]再经过排序得到最终推荐列表1[102:1.1,104:1.0,103:0.6,105:0.5,101:0.1]。
(2)通过计算机物品相似度方式计算用户的推荐向量。
通过计算机物品相似度方式计算用户的推荐向量和上面通过共现矩阵的方式差不多,就是将物品相似度矩阵代替掉共现矩阵和用户对物品的评分矩阵相乘,然后在计算推荐向量。
计算相似度矩阵:
在计算之前我们先了解一下物品相似度相关的计算方法。
对于计算物品相似度的算法有很多,要根据自己的数据模型进行选择。基于皮尔逊相关系数计算、欧几里德定理(实际上是算两点距离)、基于余弦相似度计算斯皮尔曼相关系数计算、基于谷本系数计算、基于对数似然比计算。其中谷本系数和对数似然比这两种方式主要是针对那些没有指名对物品喜欢度的数据模型进行相似度计算,也就是mahout中所指的Boolean数据模型。下面主要介绍2种,欧几里德和余弦相似度算法。
 现在关键是怎么将现有数据转化成对应的空间向量模型使之适用这些定理,这是个关键点。下面我以欧几里德定理作为例子看看那如何建立模型:
现在关键是怎么将现有数据转化成对应的空间向量模型使之适用这些定理,这是个关键点。下面我以欧几里德定理作为例子看看那如何建立模型:
第一步:将用户向量转化为物品向量
用户向量:
1[102:0.1,103:0.2,104:0.3]
2[101:0.1,102:0.7,105:0.9]
3[102:0.1,103:0.7,104:0.2]
转为为物品向量:
101[2:0.1]
102[1:0.1,2:0.7,3:0.1]
103[1:0.2,3:0.7]
104[1:0.3,3:0.2]
105[2:0.9]
第二步:
那么物品相似度计算为:

第三步:
最终得到物品相似度矩阵为:(这里省略掉没有意义的自关联相似度)

第四步:物品相似度矩阵和用户对物品的评分矩阵相乘得到推荐结果:
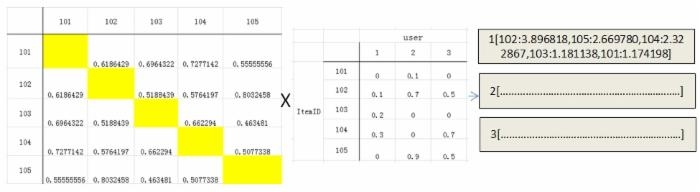
举个例子计算用户1的类似推荐列表过程:
用户1对物品101的总评分计算:
1*0+1*0.6186429+0*0.6964322+0*0.7277142+1*0.55555556=1.174198
用户1对物品102的总评分计算:
1*0.6186429+3*0+1*0.5188439+2*0.5764197+2*0.8032458=3.896818
用户1对物品103的总评分计算:
0*0.6964322+1*0.5188439+1*0+1*0.662294+0*0.463481=1.181138
用户1对物品104的总评分计算:
0*0.7277142+2*0.5764197+1*0.662294+2*0+1*0.5077338=2.322867
用户1对物品105的总评分计算:
1*0.55555556+2*0.8032458+0*0.463481+1*0.5077338=2.669780
四、共现矩阵方式的MapReduce实现
这里主要是利用MapReduce结合Mahout连的一些数据类型对共现矩阵方式的推荐方法进行实现,至于相似度矩阵方式进行推荐的在下一篇blog写。这里采用Boolean数据模型,即用户是没有对喜欢的物品进行初始打分的,我们在程序中默认都为1。
先看看整个MapReduce的数据流向图:

具体代码实现:HadoopUtil
package com.util; import java.io.IOException; import java.util.Arrays; import java.util.Iterator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.PathFilter; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapreduce.InputFormat; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.OutputFormat; import org.apache.hadoop.mapreduce.Reducer; import org.apache.mahout.common.iterator.sequencefile.PathType; import org.apache.mahout.common.iterator.sequencefile.SequenceFileDirValueIterator; import org.apache.mahout.common.iterator.sequencefile.SequenceFileValueIterator; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public final class HadoopUtil { private static final Logger log = LoggerFactory.getLogger(HadoopUtil.class); private HadoopUtil() { } public static Job prepareJob(String jobName, String[] inputPath, String outputPath, Class<? extends InputFormat> inputFormat, Class<? extends Mapper> mapper, Class<? extends Writable> mapperKey, Class<? extends Writable> mapperValue, Class<? extends OutputFormat> outputFormat, Configuration conf) throws IOException { Job job = new Job(new Configuration(conf)); job.setJobName(jobName); Configuration jobConf = job.getConfiguration(); if (mapper.equals(Mapper.class)) { throw new IllegalStateException("Can't figure out the user class jar file from mapper/reducer"); } job.setJarByClass(mapper); job.setInputFormatClass(inputFormat); job.setInputFormatClass(inputFormat); StringBuilder inputPathsStringBuilder =new StringBuilder(); for(String p : inputPath){ inputPathsStringBuilder.append(",").append(p); } inputPathsStringBuilder.deleteCharAt(0); jobConf.set("mapred.input.dir", inputPathsStringBuilder.toString()); job.setMapperClass(mapper); job.setMapOutputKeyClass(mapperKey); job.setMapOutputValueClass(mapperValue); job.setOutputKeyClass(mapperKey); job.setOutputValueClass(mapperValue); jobConf.setBoolean("mapred.compress.map.output", true); job.setNumReduceTasks(0); job.setOutputFormatClass(outputFormat); jobConf.set("mapred.output.dir", outputPath); return job; } public static Job prepareJob(String jobName, String[] inputPath, String outputPath, Class<? extends InputFormat> inputFormat, Class<? extends Mapper> mapper, Class<? extends Writable> mapperKey, Class<? extends Writable> mapperValue, Class<? extends Reducer> reducer, Class<? extends Writable> reducerKey, Class<? extends Writable> reducerValue, Class<? extends OutputFormat> outputFormat, Configuration conf) throws IOException { Job job = new Job(new Configuration(conf)); job.setJobName(jobName); Configuration jobConf = job.getConfiguration(); if (reducer.equals(Reducer.class)) { if (mapper.equals(Mapper.class)) { throw new IllegalStateException("Can't figure out the user class jar file from mapper/reducer"); } job.setJarByClass(mapper); } else { job.setJarByClass(reducer); } job.setInputFormatClass(inputFormat); StringBuilder inputPathsStringBuilder =new StringBuilder(); for(String p : inputPath){ inputPathsStringBuilder.append(",").append(p); } inputPathsStringBuilder.deleteCharAt(0); jobConf.set("mapred.input.dir", inputPathsStringBuilder.toString()); job.setMapperClass(mapper); if (mapperKey != null) { job.setMapOutputKeyClass(mapperKey); } if (mapperValue != null) { job.setMapOutputValueClass(mapperValue); } jobConf.setBoolean("mapred.compress.map.output", true); job.setReducerClass(reducer); job.setOutputKeyClass(reducerKey); job.setOutputValueClass(reducerValue); job.setOutputFormatClass(outputFormat); jobConf.set("mapred.output.dir", outputPath); return job; } public static Job prepareJob(String jobName, String[] inputPath, String outputPath, Class<? extends InputFormat> inputFormat, Class<? extends Mapper> mapper, Class<? extends Writable> mapperKey, Class<? extends Writable> mapperValue, Class<? extends Reducer> combiner, Class<? extends Reducer> reducer, Class<? extends Writable> reducerKey, Class<? extends Writable> reducerValue, Class<? extends OutputFormat> outputFormat, Configuration conf) throws IOException { Job job = new Job(new Configuration(conf)); job.setJobName(jobName); Configuration jobConf = job.getConfiguration(); if (reducer.equals(Reducer.class)) { if (mapper.equals(Mapper.class)) { throw new IllegalStateException( "Can't figure out the user class jar file from mapper/reducer"); } job.setJarByClass(mapper); } else { job.setJarByClass(reducer); } job.setInputFormatClass(inputFormat); StringBuilder inputPathsStringBuilder = new StringBuilder(); for (String p : inputPath) { inputPathsStringBuilder.append(",").append(p); } inputPathsStringBuilder.deleteCharAt(0); jobConf.set("mapred.input.dir", inputPathsStringBuilder.toString()); job.setMapperClass(mapper); if (mapperKey != null) { job.setMapOutputKeyClass(mapperKey); } if (mapperValue != null) { job.setMapOutputValueClass(mapperValue); } jobConf.setBoolean("mapred.compress.map.output", true); job.setCombinerClass(combiner); job.setReducerClass(reducer); job.setOutputKeyClass(reducerKey); job.setOutputValueClass(reducerValue); job.setOutputFormatClass(outputFormat); jobConf.set("mapred.output.dir", outputPath); return job; } public static String getCustomJobName(String className, JobContext job, Class<? extends Mapper> mapper, Class<? extends Reducer> reducer) { StringBuilder name = new StringBuilder(100); String customJobName = job.getJobName(); if (customJobName == null || customJobName.trim().isEmpty()) { name.append(className); } else { name.append(customJobName); } name.append('-').append(mapper.getSimpleName()); name.append('-').append(reducer.getSimpleName()); return name.toString(); } public static void delete(Configuration conf, Iterable<Path> paths) throws IOException { if (conf == null) { conf = new Configuration(); } for (Path path : paths) { FileSystem fs = path.getFileSystem(conf); if (fs.exists(path)) { log.info("Deleting {}", path); fs.delete(path, true); } } } public static void delete(Configuration conf, Path... paths) throws IOException { delete(conf, Arrays.asList(paths)); } public static long countRecords(Path path, Configuration conf) throws IOException { long count = 0; Iterator<?> iterator = new SequenceFileValueIterator<Writable>(path, true, conf); while (iterator.hasNext()) { iterator.next(); count++; } return count; } public static long countRecords(Path path, PathType pt, PathFilter filter, Configuration conf) throws IOException { long count = 0; Iterator<?> iterator = new SequenceFileDirValueIterator<Writable>(path, pt, filter, null, true, conf); while (iterator.hasNext()) { iterator.next(); count++; } return count; } }
先看看写的工具类:
第一步:处理原始输入数据
处理原始数据的SourceDataToItemPrefsJob作业的mapper:SourceDataToItemPrefsMapper
package com.mapper; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.mahout.math.VarLongWritable; /** * mapper输入格式:userID:itemID1 itemID2 itemID3.... * mapper输出格式:<userID,itemID> * @author 曾昭正 */ public class SourceDataToItemPrefsMapper extends Mapper<LongWritable, Text, VarLongWritable, VarLongWritable>{ //private static final Logger logger = LoggerFactory.getLogger(SourceDataToItemPrefsMapper.class); private static final Pattern NUMBERS = Pattern.compile("(\\d+)"); private String line = null; @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { line = value.toString(); if(line == null) return ; // logger.info("line:"+line); Matcher matcher = NUMBERS.matcher(line); matcher.find();//寻找第一个分组,即userID VarLongWritable userID = new VarLongWritable(Long.parseLong(matcher.group()));//这个类型是在mahout中独立进行封装的 VarLongWritable itemID = new VarLongWritable(); while(matcher.find()){ itemID.set(Long.parseLong(matcher.group())); // logger.info(userID + " " + itemID); context.write(userID, itemID); } } }
处理原始数据的SourceDataToItemPrefsJob作业的reducer:SourceDataToItemPrefsMapper
package com.reducer; import java.io.IOException; import org.apache.hadoop.mapreduce.Reducer; import org.apache.mahout.math.RandomAccessSparseVector; import org.apache.mahout.math.VarLongWritable; import org.apache.mahout.math.Vector; import org.apache.mahout.math.VectorWritable; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * reducer输入:<userID,Iterable<itemID>> * reducer输出:<userID,VecotrWriable<index=itemID,valuce=pres>....> * @author 曾昭正 */ public class SourceDataToUserVectorReducer extends Reducer<VarLongWritable, VarLongWritable, VarLongWritable, VectorWritable>{ private static final Logger logger = LoggerFactory.getLogger(SourceDataToUserVectorReducer.class); @Override protected void reduce(VarLongWritable userID, Iterable<VarLongWritable> itemPrefs,Context context) throws IOException, InterruptedException { /** * DenseVector,它的实现就是一个浮点数数组,对向量里所有域都进行存储,适合用于存储密集向量。 RandomAccessSparseVector 基于浮点数的 HashMap 实现的,key 是整形 (int) 类型,value 是浮点数 (double) 类型,它只存储向量中不为空的值,并提供随机访问。 SequentialAccessVector 实现为整形 (int) 类型和浮点数 (double) 类型的并行数组,它也只存储向量中不为空的值,但只提供顺序访问。 用户可以根据自己算法的需求选择合适的向量实现类,如果算法需要很多随机访问,应该选择 DenseVector 或者 RandomAccessSparseVector,如果大部分都是顺序访问,SequentialAccessVector 的效果应该更好。 介绍了向量的实现,下面我们看看如何将现有的数据建模成向量,术语就是“如何对数据进行向量化”,以便采用 Mahout 的各种高效的聚类算法。 */ Vector userVector = new RandomAccessSparseVector(Integer.MAX_VALUE, 100); for(VarLongWritable itemPref : itemPrefs){ userVector.set((int)itemPref.get(), 1.0f);//RandomAccessSparseVector.set(index,value),用户偏好类型为boolean类型,将偏好值默认都为1.0f } logger.info(userID+" "+new VectorWritable(userVector)); context.write(userID, new VectorWritable(userVector)); } }
第二步:将SourceDataToItemPrefsJob作业的reduce输出结果组合成共现矩阵
UserVectorToCooccurrenceJob作业的mapper:UserVectorToCooccurrenceMapper
package com.mapper; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Mapper; import org.apache.mahout.math.VarLongWritable; import org.apache.mahout.math.Vector; import org.apache.mahout.math.VectorWritable; /** * mapper输入:<userID,VecotrWriable<index=itemID,valuce=pres>....> * mapper输出:<itemID,itemID>(共现物品id对) * @author 曾昭正 */ public class UserVectorToCooccurrenceMapper extends Mapper<VarLongWritable, VectorWritable, IntWritable, IntWritable>{ @Override protected void map(VarLongWritable userID, VectorWritable userVector,Context context) throws IOException, InterruptedException { Iterator<Vector.Element> it = userVector.get().nonZeroes().iterator();//过滤掉非空元素 while(it.hasNext()){ int index1 = it.next().index(); Iterator<Vector.Element> it2 = userVector.get().nonZeroes().iterator(); while(it2.hasNext()){ int index2 = it2.next().index(); context.write(new IntWritable(index1), new IntWritable(index2)); } } } }
UserVectorToCooccurrenceJob作业的reducer:UserVectorToCoocurrenceReducer
package com.reducer; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Reducer; import org.apache.mahout.cf.taste.hadoop.item.VectorOrPrefWritable; import org.apache.mahout.math.RandomAccessSparseVector; import org.apache.mahout.math.Vector; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * reducer输入:<itemID,Iterable<itemIDs>> * reducer输出:<mainItemID,Vector<coocItemID,coocTime(共现次数)>....> * @author 曾昭正 */ public class UserVectorToCoocurrenceReducer extends Reducer<IntWritable, IntWritable, IntWritable, VectorOrPrefWritable>{ private static final Logger logger = LoggerFactory.getLogger(UserVectorToCoocurrenceReducer.class); @Override protected void reduce(IntWritable mainItemID, Iterable<IntWritable> coocItemIDs,Context context) throws IOException, InterruptedException { Vector coocItemIDVectorRow = new RandomAccessSparseVector(Integer.MAX_VALUE,100); for(IntWritable coocItem : coocItemIDs){ int itemCoocTime = coocItem.get(); coocItemIDVectorRow.set(itemCoocTime,coocItemIDVectorRow.get(itemCoocTime)+1.0);//将共现次数累加 } logger.info(mainItemID +" "+new VectorOrPrefWritable(coocItemIDVectorRow)); context.write(mainItemID, new VectorOrPrefWritable(coocItemIDVectorRow));//记录mainItemID的完整共现关系 } }
第三步:将SourceDataToItemPrefsJob作业的reduce输出结果进行分割
userVecotrSplitJob作业的mapper:UserVecotrSplitMapper
package com.mapper; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Mapper; import org.apache.mahout.cf.taste.hadoop.item.VectorOrPrefWritable; import org.apache.mahout.math.VarLongWritable; import org.apache.mahout.math.Vector; import org.apache.mahout.math.Vector.Element; import org.apache.mahout.math.VectorWritable; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * 将用户向量分割,以便和物品的共现向量进行合并 * mapper输入:<userID,Vector<itemIDIndex,preferenceValuce>....> * reducer输出:<itemID,Vecotor<userID,preferenceValuce>....> * @author 曾昭正 */ public class UserVecotrSplitMapper extends Mapper<VarLongWritable, VectorWritable, IntWritable, VectorOrPrefWritable>{ private static final Logger logger = LoggerFactory.getLogger(UserVecotrSplitMapper.class); @Override protected void map(VarLongWritable userIDWritable, VectorWritable value,Context context) throws IOException, InterruptedException { IntWritable itemIDIndex = new IntWritable(); long userID = userIDWritable.get(); Vector userVector = value.get(); Iterator<Element> it = userVector.nonZeroes().iterator();//只取非空用户向量 while(it.hasNext()){ Element e = it.next(); int itemID = e.index(); itemIDIndex.set(itemID); float preferenceValuce = (float) e.get(); logger.info(itemIDIndex +" "+new VectorOrPrefWritable(userID,preferenceValuce)); context.write(itemIDIndex, new VectorOrPrefWritable(userID,preferenceValuce)); } } }
第四步:将userVecotrSplitJob和UserVectorToCooccurrenceJob作业的输出结果合并
combineUserVectorAndCoocMatrixJob作业的mapper:CombineUserVectorAndCoocMatrixMapper
package com.mapper; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Mapper; import org.apache.mahout.cf.taste.hadoop.item.VectorOrPrefWritable; /** * 将共现矩阵和分割后的用户向量进行合并,以便计算部分的推荐向量 * 这个mapper其实没有什么逻辑处理功能,只是将数据按照输入格式输出 * 注意:这里的mapper输入为共现矩阵和分割后的用户向量计算过程中的共同输出的2个目录 * mapper输入:<itemID,Vecotor<userID,preferenceValuce>> or <itemID,Vecotor<coocItemID,coocTimes>> * mapper输出:<itemID,Vecotor<userID,preferenceValuce>/Vecotor<coocItemID,coocTimes>> * @author 曾昭正 */ public class CombineUserVectorAndCoocMatrixMapper extends Mapper<IntWritable, VectorOrPrefWritable, IntWritable, VectorOrPrefWritable>{ @Override protected void map(IntWritable itemID, VectorOrPrefWritable value,Context context) throws IOException, InterruptedException { context.write(itemID, value); } }
combineUserVectorAndCoocMatrixJob作业的CombineUserVectorAndCoocMatrixReducer
package com.reducer; import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Reducer; import org.apache.mahout.cf.taste.hadoop.item.VectorAndPrefsWritable; import org.apache.mahout.cf.taste.hadoop.item.VectorOrPrefWritable; import org.apache.mahout.math.Vector; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * 将共现矩阵和分割后的用户向量进行合并,以便计算部分的推荐向量 * @author 曾昭正 */ public class CombineUserVectorAndCoocMatrixReducer extends Reducer<IntWritable, VectorOrPrefWritable, IntWritable, VectorAndPrefsWritable>{ private static final Logger logger = LoggerFactory.getLogger(CombineUserVectorAndCoocMatrixReducer.class); @Override protected void reduce(IntWritable itemID, Iterable<VectorOrPrefWritable> values,Context context) throws IOException, InterruptedException { VectorAndPrefsWritable vectorAndPrefsWritable = new VectorAndPrefsWritable(); List<Long> userIDs = new ArrayList<Long>(); List<Float> preferenceValues = new ArrayList<Float>(); Vector coocVector = null; Vector coocVectorTemp = null; Iterator<VectorOrPrefWritable> it = values.iterator(); while(it.hasNext()){ VectorOrPrefWritable e = it.next(); coocVectorTemp = e.getVector() ; if(coocVectorTemp == null){ userIDs.add(e.getUserID()); preferenceValues.add(e.getValue()); }else{ coocVector = coocVectorTemp; } } if(coocVector != null){ //这个需要注意,根据共现矩阵的计算reduce聚合之后,到了这个一个Reudce分组就有且只有一个vecotr(即共现矩阵的一列或者一行,这里行和列是一样的)了。 vectorAndPrefsWritable.set(coocVector, userIDs, preferenceValues); logger.info(itemID+" "+vectorAndPrefsWritable); context.write(itemID, vectorAndPrefsWritable); } } }
第五步:将combineUserVectorAndCoocMatrixJob作业的输出结果生成推荐列表
caclPartialRecomUserVectorJob作业的mapper:CaclPartialRecomUserVectorMapper
package com.mapper; import java.io.IOException; import java.util.List; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Mapper; import org.apache.mahout.cf.taste.hadoop.item.VectorAndPrefsWritable; import org.apache.mahout.math.VarLongWritable; import org.apache.mahout.math.Vector; import org.apache.mahout.math.VectorWritable; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * 计算部分用户推荐向量 * @author 曾昭正 */ public class CaclPartialRecomUserVectorMapper extends Mapper<IntWritable,VectorAndPrefsWritable, VarLongWritable, VectorWritable>{ private static final Logger logger = LoggerFactory.getLogger(CaclPartialRecomUserVectorMapper.class); @Override protected void map(IntWritable itemID, VectorAndPrefsWritable values,Context context) throws IOException, InterruptedException { Vector coocVectorColumn = values.getVector(); List<Long> userIDs = values.getUserIDs(); List<Float> preferenceValues = values.getValues(); for(int i = 0; i< userIDs.size(); i++){ long userID = userIDs.get(i); float preferenceValue = preferenceValues.get(i); logger.info("userID:" + userID); logger.info("preferenceValue:"+preferenceValue); //将共现矩阵中userID对应的列相乘,算出部分用户对应的推荐列表分数 Vector preferenceParScores = coocVectorColumn.times(preferenceValue); context.write(new VarLongWritable(userID), new VectorWritable(preferenceParScores)); } } }
caclPartialRecomUserVectorJob作业的combiner:ParRecomUserVectorCombiner
package com.reducer; import java.io.IOException; import org.apache.hadoop.mapreduce.Reducer; import org.apache.mahout.math.VarLongWritable; import org.apache.mahout.math.Vector; import org.apache.mahout.math.VectorWritable; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * 将计算部分用户推荐向量的结果进行合并,将userID对应的贡现向量的分值进行相加(注意:这个只是将一个map的输出进行合并,所以这个也是只部分结果) * @author 曾昭正 */ public class ParRecomUserVectorCombiner extends Reducer<VarLongWritable, VectorWritable, VarLongWritable, VectorWritable>{ private static final Logger logger = LoggerFactory.getLogger(ParRecomUserVectorCombiner.class); @Override protected void reduce(VarLongWritable userID, Iterable<VectorWritable> coocVectorColunms,Context context) throws IOException, InterruptedException { Vector vectorColunms = null; for(VectorWritable coocVectorColunm : coocVectorColunms){ vectorColunms = vectorColunms == null ? coocVectorColunm.get() : vectorColunms.plus(coocVectorColunm.get()); } logger.info(userID +" " + new VectorWritable(vectorColunms)); context.write(userID, new VectorWritable(vectorColunms)); } }
caclPartialRecomUserVectorJob作业的reducer:MergeAndGenerateRecommendReducer
package com.reducer; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import java.util.Iterator; import java.util.List; import java.util.PriorityQueue; import java.util.Queue; import org.apache.hadoop.mapreduce.Reducer; import org.apache.mahout.cf.taste.hadoop.RecommendedItemsWritable; import org.apache.mahout.cf.taste.impl.recommender.ByValueRecommendedItemComparator; import org.apache.mahout.cf.taste.impl.recommender.GenericRecommendedItem; import org.apache.mahout.cf.taste.recommender.RecommendedItem; import org.apache.mahout.math.VarLongWritable; import org.apache.mahout.math.Vector; import org.apache.mahout.math.Vector.Element; import org.apache.mahout.math.VectorWritable; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * 合并所有已经评分的共现矩阵 * @author 曾昭正 */ public class MergeAndGenerateRecommendReducer extends Reducer<VarLongWritable, VectorWritable, VarLongWritable, RecommendedItemsWritable>{ private static final Logger logger = LoggerFactory.getLogger(MergeAndGenerateRecommendReducer.class); private int recommendationsPerUser; @Override protected void setup(Context context) throws IOException, InterruptedException { recommendationsPerUser = context.getConfiguration().getInt("recomandItems.recommendationsPerUser", 5); } @Override protected void reduce(VarLongWritable userID, Iterable<VectorWritable> cooVectorColumn,Context context) throws IOException, InterruptedException { //分数求和合并 Vector recommdVector = null; for(VectorWritable vector : cooVectorColumn){ recommdVector = recommdVector == null ? vector.get() : recommdVector.plus(vector.get()); } //对推荐向量进行排序,为每个UserID找出topM个推荐选项(默认找出5个),此队列按照item对应的分数进行排序 //注意下:PriorityQueue队列的头一定是最小的元素,另外这个队列容量增加1是为了为添加更大的新元素时使用的临时空间 Queue<RecommendedItem> topItems = new PriorityQueue<RecommendedItem>(recommendationsPerUser+1, ByValueRecommendedItemComparator.getInstance()); Iterator<Element> it = recommdVector.nonZeroes().iterator(); while(it.hasNext()){ Element e = it.next(); int itemID = e.index(); float preValue = (float) e.get(); //当队列容量小于推荐个数,往队列中填item和分数 if(topItems.size() < recommendationsPerUser){ topItems.add(new GenericRecommendedItem(itemID, preValue)); } //当前item对应的分数比队列中的item的最小分数大,则将队列头原始(即最小元素)弹出,并且将当前item:分数加入队列 else if(preValue > topItems.peek().getValue()){ topItems.add(new GenericRecommendedItem(itemID, preValue)); //弹出头元素(最小元素) topItems.poll(); } } //重新调整队列的元素的顺序 List<RecommendedItem> recommdations = new ArrayList<RecommendedItem>(topItems.size()); recommdations.addAll(topItems);//将队列中所有元素添加即将排序的集合 Collections.sort(recommdations,ByValueRecommendedItemComparator.getInstance());//排序 //输出推荐向量信息 logger.info(userID+" "+ new RecommendedItemsWritable(recommdations)); context.write(userID, new RecommendedItemsWritable(recommdations)); } }
第六步:组装各个作业关系
PackageRecomendJob
package com.mapreduceMain; import java.io.IOException; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import org.apache.mahout.cf.taste.hadoop.RecommendedItemsWritable; import org.apache.mahout.cf.taste.hadoop.item.VectorAndPrefsWritable; import org.apache.mahout.cf.taste.hadoop.item.VectorOrPrefWritable; import org.apache.mahout.math.VarLongWritable; import org.apache.mahout.math.VectorWritable; import com.mapper.CaclPartialRecomUserVectorMapper; import com.mapper.CombineUserVectorAndCoocMatrixMapper; import com.mapper.UserVecotrSplitMapper; import com.mapper.UserVectorToCooccurrenceMapper; import com.mapper.SourceDataToItemPrefsMapper; import com.reducer.CombineUserVectorAndCoocMatrixReducer; import com.reducer.MergeAndGenerateRecommendReducer; import com.reducer.ParRecomUserVectorCombiner; import com.reducer.UserVectorToCoocurrenceReducer; import com.reducer.SourceDataToUserVectorReducer; import com.util.HadoopUtil; /** * 组装各个作业组件,完成推荐作业 * @author 曾昭正 */ public class PackageRecomendJob extends Configured implements Tool{ String[] dataSourceInputPath = {"/user/hadoop/z.zeng/distruteItemCF/dataSourceInput"}; String[] uesrVectorOutput = {"/user/hadoop/z.zeng/distruteItemCF/uesrVectorOutput/"}; String[] userVectorSpliltOutPut = {"/user/hadoop/z.zeng/distruteItemCF/userVectorSpliltOutPut"}; String[] cooccurrenceMatrixOuptPath = {"/user/hadoop/z.zeng/distruteItemCF/CooccurrenceMatrixOuptPath"}; String[] combineUserVectorAndCoocMatrixOutPutPath = {"/user/hadoop/z.zeng/distruteItemCF/combineUserVectorAndCoocMatrixOutPutPath"}; String[] caclPartialRecomUserVectorOutPutPath = {"/user/hadoop/z.zeng/distruteItemCF/CaclPartialRecomUserVectorOutPutPath"}; protected void setup(Configuration configuration) throws IOException, InterruptedException { FileSystem hdfs = FileSystem.get(URI.create("hdfs://cluster-master"), configuration); Path p1 = new Path(uesrVectorOutput[0]); Path p2 = new Path(userVectorSpliltOutPut[0]); Path p3 = new Path(cooccurrenceMatrixOuptPath[0]); Path p4 = new Path(combineUserVectorAndCoocMatrixOutPutPath[0]); Path p5 = new Path(caclPartialRecomUserVectorOutPutPath[0]); if (hdfs.exists(p1)) { hdfs.delete(p1, true); } if (hdfs.exists(p2)) { hdfs.delete(p2, true); } if (hdfs.exists(p3)) { hdfs.delete(p3, true); } if (hdfs.exists(p4)) { hdfs.delete(p4, true); } if (hdfs.exists(p5)) { hdfs.delete(p5, true); } } @Override public int run(String[] args) throws Exception { Configuration conf=getConf(); //获得配置文件对象 setup(conf); // DistributedCache.addArchiveToClassPath(new Path("/user/hadoop/z.zeng/distruteItemCF/lib"), conf); //配置计算用户向量作业 Job wikipediaToItemPrefsJob = HadoopUtil.prepareJob( "WikipediaToItemPrefsJob", dataSourceInputPath, uesrVectorOutput[0], TextInputFormat.class, SourceDataToItemPrefsMapper.class, VarLongWritable.class, VarLongWritable.class, SourceDataToUserVectorReducer.class, VarLongWritable.class, VectorWritable.class, SequenceFileOutputFormat.class, conf); //配置计算共现向量作业 Job userVectorToCooccurrenceJob = HadoopUtil.prepareJob( "UserVectorToCooccurrenceJob", uesrVectorOutput, cooccurrenceMatrixOuptPath[0], SequenceFileInputFormat.class, UserVectorToCooccurrenceMapper.class, IntWritable.class, IntWritable.class, UserVectorToCoocurrenceReducer.class, IntWritable.class, VectorOrPrefWritable.class, SequenceFileOutputFormat.class, conf); //配置分割用户向量作业 Job userVecotrSplitJob = HadoopUtil.prepareJob( "userVecotrSplitJob", uesrVectorOutput, userVectorSpliltOutPut[0], SequenceFileInputFormat.class, UserVecotrSplitMapper.class, IntWritable.class, VectorOrPrefWritable.class, SequenceFileOutputFormat.class, conf); //合并共现向量和分割之后的用户向量作业 //这个主意要将分割用户向量和共现向量的输出结果一起作为输入 String[] combineUserVectorAndCoocMatrixIutPutPath = {cooccurrenceMatrixOuptPath[0],userVectorSpliltOutPut[0]}; Job combineUserVectorAndCoocMatrixJob = HadoopUtil.prepareJob( "combineUserVectorAndCoocMatrixJob", combineUserVectorAndCoocMatrixIutPutPath, combineUserVectorAndCoocMatrixOutPutPath[0], SequenceFileInputFormat.class, CombineUserVectorAndCoocMatrixMapper.class, IntWritable.class, VectorOrPrefWritable.class, CombineUserVectorAndCoocMatrixReducer.class, IntWritable.class, VectorAndPrefsWritable.class, SequenceFileOutputFormat.class, conf); //计算用户推荐向量 Job caclPartialRecomUserVectorJob= HadoopUtil.prepareJob( "caclPartialRecomUserVectorJob", combineUserVectorAndCoocMatrixOutPutPath, caclPartialRecomUserVectorOutPutPath[0], SequenceFileInputFormat.class, CaclPartialRecomUserVectorMapper.class, VarLongWritable.class, VectorWritable.class, ParRecomUserVectorCombiner.class,//为map设置combiner减少网络IO MergeAndGenerateRecommendReducer.class, VarLongWritable.class, RecommendedItemsWritable.class, TextOutputFormat.class, conf); //串联各个job if(wikipediaToItemPrefsJob.waitForCompletion(true)){ if(userVectorToCooccurrenceJob.waitForCompletion(true)){ if(userVecotrSplitJob.waitForCompletion(true)){ if(combineUserVectorAndCoocMatrixJob.waitForCompletion(true)){ int rs = caclPartialRecomUserVectorJob.waitForCompletion(true) ? 1 :0; return rs; }else{ throw new Exception("合并共现向量和分割之后的用户向量作业失败!!"); } }else{ throw new Exception("分割用户向量作业失败!!"); } }else{ throw new Exception("计算共现向量作业失败!!"); } }else{ throw new Exception("计算用户向量作业失败!!"); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { try { int returnCode = ToolRunner.run(new PackageRecomendJob(),args); System.exit(returnCode); } catch (Exception e) { } } }
五、总结
本blog主要说了下itemBase推荐算法的一些概念,以及如何多现有数据进行建模。其中对共现矩阵方式的推荐用MapReduce结合Mahout的内置数据类型进行了实现。写完这篇blog和对算法实现完毕后,发现Mapreduce编程虽然数据模型非常简单,只有2个过程:数据的分散与合并,但是在分散与合并的过程中可以使用自定义的各种数据组合类型使其能够完成很多复杂的功能。
参考文献:《Mahout in action》、《推荐引擎实践》
来源: <http://www.tuicool.com/articles/BZVBRz>