遗传学算法概述
从之前转载的博客《非常好的理解遗传算法的例子》中可以知道,遗传学算法主要有6个步骤:
1. 个体编码
2. 初始群体
3. 适应度计算
4. 选择运算
5. 交叉运算
6. 变异运算
这是一个仿生的过程,模仿生物进化和自然选择。在该算法中,个体编码就相当于生物最基本的组成——基因,初始群体就是刚开始那些个原始的生物体。
在恶劣的环境中,适者生存的自然法则将让适应能力更好的生物继续存活繁衍下去,而适应能力差的生物将会被淘汰。因此遗传算法通过计算适应度来模拟这个自然选择的过程,用于筛选优良的个体保留下来。光这么讲也许太抽象,可能读者也无法知道具体如何实现的,也不知道这个适应度是如何去评价去个体的优劣程度的。下面举例个简单的例子来说明,如下图:假如现在要求一条曲线方程的最大值,并且已知有若干个点。那么曲线的值也就是求最大值过程中的适应度,因为值越大就越接近最大值,其适应度就越好。因此在这个求最大值的过程中,曲线对应的值可以直接作为适应度。在下一步选择运算过程中,这些适应能力好的个体也有更高的概率被保留下来。
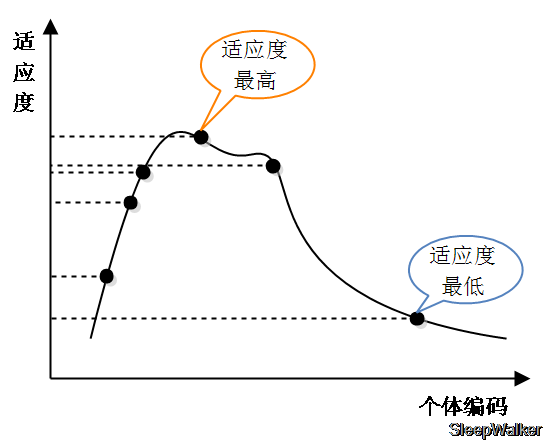
选择运算就是自然选择的过程。在适应度计算过程中,各个个体的适应能力已经知道,因此部分适应能力差的个体就将会被淘汰。就想自然选择一样,大自然不会对生物体适应能力进行排序,然后一刀切全部淘汰弱者。在选择运算中,算法也是根据适应度来确定一个选择概率,按照概率来确定哪些个体允许保留下来。自然地,适应度高的,被保留下来的概率也更高,而适应度低的保留下来的可能性就越低。
进行选择之后,保留下来的个体就像生物一样,需要在自己的生命周期内繁衍后代来延续自己的物种。然后,就是脸红心跳的配对阶段了,两个个体之间需要贡献各自的染色体进行交换。这一过程中新的个体经过交叉运算获得由父母双方部分基因的组合,新的个体中基因来自于父母双方。当然了,算法中交差运算没有男女之分,交叉运算后所有的个体都是交叉运算产生的新个体,原本的个体被新个体代替不进入下一次迭代。如《非常好的理解遗传算法的例子》中过程5的描述:

交叉的时候进行交换基因的位置也是随机产生的,交换个体同样按照各自适应度以一定概率进行选择。因此适应度高的个体进行交差运算的概率也更高,这个在动物界比较普遍,即强壮的首领拥有交配权,以便优良基因更多机会保留下去。并且交叉本身也有一定发生概率,如果不进行交叉,那么交叉的结果就是新个体与原个体相同。这个理解起来也方便,就是说,要是进行交叉了,新个体为交叉结果;那要是不孕育新个体呢,那抱歉,你们两个个体还要经过下一次迭代。
最后,就是生物进化的过程了,这是一个小概率事件,但却是造就如今这样美丽而伟大的生命世界的关键。变异是随机的,因为随机,因此绝大部分变异都是恶性的,但也正是这种不确定性才导致了生物的多样性,让我们的世界变得美妙多彩。因为有自然选择的过程,变异后恶化的基因会被抛弃,因此,整个生物界依靠这几个关键步骤保持着不断进化,不断适应的趋势。但是,同样地,我们可以预料到,在变异运算这一步中,变异出现的概率会非常小,否则整个算法也就随机了。说了那么多,归结起来,变异在算法中的体现说白了就是按照一个小概率去挑选一个个体,然后将其某个编码后的码字取个反,当然,这是在二进制编码的情况下来说啦。
本身遗传学算法也是一门很复杂的学问,研究到现在,求解过程越来越像一个生命体的进化过程,但是基本思想还是如上述所说。同样地,下面我也将上述最基础的遗传学算法用matlab进行实现,各位读者也可以参照着代码来理解算法。
Matlab算法实现
下面演示,利用遗传学算法来求解最佳分割阈值。这个方法参考论文《Infrared Image Segmentation Based on Otsu and Genetic Algorithm》,该论文基于大津法和遗传算法来分割红外图像。不说算法有多好,其实也差不多,还不一定有Otsu来得直接(抱歉,我喜欢喷一喷(*^__^*) ),但是通过这个案例能够有效地描述遗传算法的使用。这里要感谢一下我师兄将该文献翻译的成中文,让我看起来方便多了。
大津法大家应该都听说过,目的是求最优的前景和背景的分界面,在图像分割算法中,大津法也是最有名的算法,个人觉得,没有之一。这里实际是使用遗传算法来求这个最优的分界面,就如上述我举例说求曲线的最大值一样,只是这里面最适应度的计算不是那么直接。下面从总体到各部分细节一一介绍。
(一)分割算法
这里将文中的算法命名为OtsuWithGenetic,算法不需要人为添加任何参数来辅助运算。从算法的名称来看,就可以知道,算法结合了大津法和遗传算法两者的特征。因此,在进行遗传算法的迭代流程之前,需要计算图像的直方图。而进行遗传学迭代运算的过程,在本案例中,我将其封装成一个名为BestThresh的函数,它的输入同样仅需要图像的直方图就可以了。在求取最佳阈值之后,就对图像进行二值化,得到最终结果图。
所以分割算法整体分为三个步骤:
1. 计算图像直方图
2. 利用遗传学算法求最佳阈值
3. 图像分割,进行二值化
function ImOut = OtsuWithGenetic(ImOriginal) % 大津分割算法,结合遗传算法 % 在性能方面暂未进行相应优化,只对求解方程进行了优化 % 部分代码结构比较凌乱 ImGray = double(rgb2gray(ImOriginal)); %转换为双精度灰度图 [m,n] = size(ImGray); %计算图片的尺寸 ImHist = zeros(1,256); %灰度直方图 ImOut = zeros(m,n); %分割结果图像 % 统计各灰度级的像素点个数,计算灰度直方图 for i=1:m for j=1:n ImHist(ImGray(i,j)+1) = ImHist(ImGray(i,j)+1)+1; end end th = BestThresh(ImHist); % 分割图像,高于阈值为前景255,低于阈值为背景0 for i = 1:m for j = 1:n if (ImGray(i,j)+1>th) ImOut(i,j) = 255; else ImOut(i,j) = 0; end end end ImOut=uint8(ImOut); %读入读出变换 end
(二)遗传算法求解大津最佳阈值
这一步实际上就是BestThresh函数的描述。从整个函数的代码中我们可以很清楚地看到遗传学算法描述中的6个步骤。
function bestindividual = BestThresh(ImHist) popsize=40; %群体大小 chromlength=8; %字符串长度(个体长度) pc=0.9; %交叉概率 pm=0.001; %变异概率 pop = InitEntity(popsize,chromlength); %随机产生初始群体 for i = 1:50 %50为迭代次数 [objvalue] = FitnessValue(pop, ImHist); %计算目标函数 fitvalue = CalFitValue(objvalue); %计算群体中每个个体的适应度 [newpop] = Selection(pop,fitvalue); %选择 [newpop] = CrossOver(newpop,pc); %交叉 [newpop] = Mutation(newpop,pm); %变异 pop = newpop; end
[bestindividual,bestfit] = BestEntity(pop,fitvalue); %求出群体中适应值最大的个体及其适应值
bestindividual = DecodeChrom(bestindividual,1,chromlength);
end这里在一开始定义了四个参数:popsize, chromlength, pc, pm。具体含义见注释,这里重点介绍pc和pm两个参数。pc是交叉概率,pm是变异概率,在上述描述中我们说到,交叉和变异都是按照一定概率进行的,从这里也可以看到,两者的概率之间的差别。这里我默认将两者的概率定为了0.9和0.001,同样,迭代次数和群体的大小也定死了,实际上,运算次数再多,群体再大,也是浪费运算资源。
从代码中看到,在初始化完个体后,就按顺序进入迭代运算,迭代经过适应度的计算、选择运算、交叉运算和变异运算。其中计算目标函数和个体适应度计算实际是一个内容,CalFitValue实质是进行了矫正防止出现负数,而FitnessValue是适应度计算函数。
迭代结束以后,将适应度最大的作为最终的阈值,并且经过解码之后转换为实际的灰度值。
1. 初始化群体+个体编码
在本案例中,需要计算最佳的阈值,也就是计算作为阈值的那个最优的灰度值。对灰度值进行二进制编码获得随机的40个群体代码如下:
% 1 初始化群体(编码) % popsize表示群体的大小,chromlength表示染色体的长度(二值数的长度) function entities = InitEntity(entitySize,chromLength) % rand随机产生随机数矩阵,round将其二值化 entities = round(rand(entitySize, chromLength)); end
该函数生成一个40行的矩阵,代码40个不同的初始个体;每个个体进行8位二进制编码,因此像素灰度本身也仅有8位深度。
2. 计算适应度
适应度的计算参考论文当中适应度函数
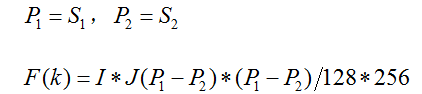
这里这里,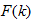 是适应度函数,
是适应度函数,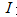 是目标图像像素数目,
是目标图像像素数目,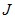 是背景图像像素数目;
是背景图像像素数目;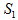 是目标图像像素总和,
是目标图像像素总和,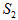 是背景图像像素总和。
是背景图像像素总和。
% 2 计算适应函数 % 实现目标函数的计算 function [objvalue] = FitnessValue(pop, Imhist) graysum = Imhist.*(0:1:255); % 各灰度值像素总和 x = DecodeChrom(pop,1,8);% 将pop每行转化成十进制数 loop = size(pop,1); objvalue = zeros(loop,1); for i = 1 : loop P1 = sum(graysum(x(i)+1 : 255)); P2 = sum(graysum(1 : uint8(x(i)))); I = sum(Imhist(x(i)+1 : 255)); J = sum(Imhist(1 : uint8(x(i)))); objvalue(i) = I * J * ((P1-P2)^2) * 2 ;%计算目标函数值 end end
function fitValue = CalFitValue(objValue) Cmin = 0; num = size(objValue,1); fitValue = zeros(1,num); for i = 1 : num if objValue(i) + Cmin > 0 temp = Cmin + objValue(i); else temp = 0.0; end fitValue(i) = temp; end end
3. 选择运算
通过计算得到的适应度就可以知道各个体的适应能力,将这些适应度进行累加,各个体就对应于一个区间。将累加结果进行归一化,然后用随机函数来进行选择,落入哪个区间就选择区间对应的个体。
% 3 选择复制 function [selectedEntities] = Selection(entities,fitValue) totalFit = sum(fitValue); %求适应值之和 fitValue = fitValue / totalFit; %单个个体被选择的概率 fitValue = cumsum(fitValue); %如 fitValue=[1 2 3 4],则 cumsum(fitValue)=[1 3 6 10] [num,cols] = size(entities); ms = rand(num,1); %产生用于选择的随机数 selectedEntities = zeros(num,cols); %初始化选择后的个体大小 for i = 1 : num for j = 1 : num if ms(i) < fitValue(j) selectedEntities(i,:) = entities(j,:); break; end end end end
4. 交叉运算
交叉运算利用一对个体产生新个体,函数如下:
% 4 交叉 % 群体中两个个体进行一定的概率 pc 的交叉,交换基因起始位置cpoint随机 function newEntities = CrossOver(entities,pc) [num, cols]= size(entities); newEntities = ones(size(entities)); for i = 1 : 2 : num-1 if(rand < pc) cpoint = round(rand*cols); % 随机产生交换起始位置 newEntities(i,:) = [entities(i,1:cpoint), entities(i+1,cpoint+1:cols)]; newEntities(i+1,:) = [entities(i+1,1:cpoint), entities(i,cpoint+1:cols)]; else newEntities(i,:) = entities(i,:); newEntities(i+1,:) = entities(i+1,:); end end end
5. 变异运算
在经过交叉运算以后,还要进行编译运算,由于是二进制编码,变异运算就可以直接将变异位置的二进制数取反。
% 5 变异 function [newEntities] = Mutation(entities,pm) [num, cols] = size(entities); newEntities = ones(size(entities)); for i = 1 : num if(rand < pm) mpoint = round(rand*cols); % 计算变异位置 if mpoint <= 0 mpoint = 1; end newEntities(i) = entities(i); if any(newEntities(i,mpoint)) == 0 % 进行二进制取反 newEntities(i,mpoint) = 1; else newEntities(i,mpoint) = 0; end else newEntities(i,:) = entities(i,:); end end end
6. 计算最优值
在迭代结束后,所有的个体基本上呈现向最优值靠拢的趋势,这时候需要通过比较来取其中的最大值,作为最优解。这一步是一个比较过程,原理很简单:
% 6 求群体中对应的最大适应值 function [bestEntity,bestFit] = BestEntity(entities, fitValue) num = size(entities, 1); bestEntity = entities(1,:); bestFit = fitValue(1); for i = 2 : num if fitValue(i) > bestFit bestEntity = entities(i,:); bestFit = fitValue(i); end end end
(三)二进制转换函数
在运算中,由于使用数组来表示二进制编码数据,因此在运算过程中经常需要进行二进制与十进制之间的转换,转换函数如下:
% 将二进制编码转换成十进制 function decimals = DecodeChrom(entities,spoint,length) temp = entities(:, spoint:spoint+length-1); decimals = DecodeBinary(temp); end % 将二进制转化为十进制 function decimals = DecodeBinary(pop) [num,cols] = size(pop); temp = zeros(num,cols); for i = 1 : cols temp(:,i) = 2.^(cols-i) .* pop(:,i); end decimals = sum(temp,2); end