聚类分析的K均值算法(Python实现)
聚类分析仅根据在数据中发现的描述对象及其关系的信息,将数据分组。其目标是,组内的对象之间是相似的,而不同组中的对象是不同的。
K均值用于n维空间中的对象,它只需要对象之间的临近性度量,例如使用欧几里德距离,可以用于广泛的数据,但是它属于不稳定的算法。
我们为了说明原理,降低复杂性,计算二维空间的K均值(平面中的点)。
数据使用Excel存储,转换为CSV文件,使用numpy中的loadtxt方法进行读取,并使用matplotlib进行显示。
matplotlib的安装详见博客:http://my.oschina.net/bery/blog/203595
import numpy as np import pylab as pl x, y = np.loadtxt('2.csv', delimiter=',', unpack=True) pl.plot(x, y, 'o') pl.show()
原始点的图像如下图所示:

从图像可以看出数据分为3个簇应该是最合适的,但是假如数据量很大或者维数很多的情况下,我们用眼睛是没有办法区分这些的,一个用来确定簇个数的方法就是使用穷举方法,有一个经验法则就是簇的个数不超过n的平方根(n为点数),我们可以使用目标函数对其进行验证,以获取最佳的簇个数。
我们使用误差的平方和(Sum of the Squared Error, SSE)作为度量的目标函数,SSE的形式化定义如下

下面calc_sse及是计算SSE的代码
#计算SSE def calc_sse(x, y, k_count): count = len(x) #点的个数 k = rd.sample(range(count), k_count) #随机选择K个点 k_point = [[x[i], [y[i]]] for i in k] k_point.sort() #保证有序 sse = [[] for i in range(k_count)] while True: ka = [[] for i in range(k_count)] #存储每个簇的索引 sse = [[] for i in range(k_count)] #遍历所有点 for i in range(count): cp = [x[i], y[i]] #当前点 #计算cp点到所有质心的距离 _sse = [distance(k_point[j], cp) for j in range(k_count)] #cp点到那个质心最近 min_index = _sse.index(min(_sse)) #把cp点并入第i簇 ka[min_index].append(i) sse[min_index].append(min(_sse)) #更换质心 k_new = [] for i in range(k_count): _x = sum([x[j] for j in ka[i]]) / len(ka[i]) _y = sum([y[j] for j in ka[i]]) / len(ka[i]) k_new.append([_x, _y]) k_new.sort() #排序 #更换质心 if (k_new != k_point): k_point = k_new else: break s =0 for i in range(k_count): s += sum(sse[i]) return s
SSE曲线的结果显示如下:
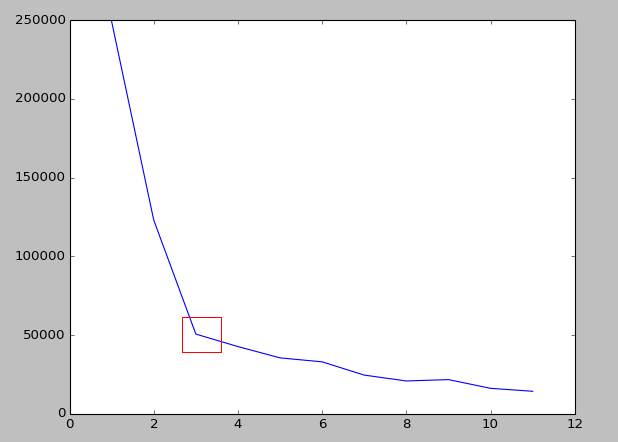
我们可以通过SSE曲线的拐点判断最佳的簇个数,对于我们的数据可以判断,最佳簇个数是3.
然后我们可以通过初始化3个质心,进行K均值的计算。
#K均值算法 def k_means(x, y, k_count): count = len(x) #点的个数 #随机选择K个点 k = rd.sample(range(count), k_count) k_point = [[x[i], [y[i]]] for i in k] #保证有序 k_point.sort() while True: km = [[] for i in range(k_count)] #存储每个簇的索引 #遍历所有点 for i in range(count): cp = [x[i], y[i]] #当前点 #计算cp点到所有质心的距离 _sse = [distance(k_point[j], cp) for j in range(k_count)] #cp点到那个质心最近 min_index = _sse.index(min(_sse)) #把cp点并入第i簇 km[min_index].append(i) #更换质心 k_new = [] for i in range(k_count): _x = sum([x[j] for j in km[i]]) / len(km[i]) _y = sum([y[j] for j in km[i]]) / len(km[i]) k_new.append([_x, _y]) k_new.sort() #排序 if (k_new != k_point): k_point = k_new else: return km
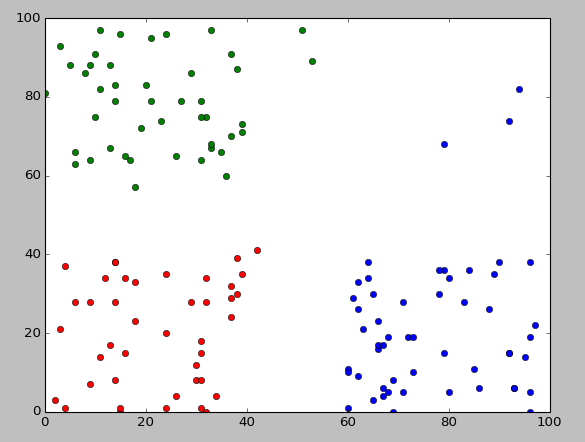
最后运行结果如图:
完整代码下载: