转自:http://my.oschina.net/u/189445/blog/595232
两个月前使用过hbase,现在最基本的命令都淡忘了,留一个备查~
| hbase shell命令 | 描述 |
| alter | 修改列族(column family)模式 |
| count | 统计表中行的数量 |
| create | 创建表 |
| describe | 显示表相关的详细信息 |
| delete | 删除指定对象的值(可以为表,行,列对应的值,另外也可以指定时间戳的值) |
| deleteall | 删除指定行的所有元素值 |
| disable | 使表无效 |
| drop | 删除表 |
| enable | 使表有效 |
| exists | 测试表是否存在 |
| exit | 退出hbase shell |
| get | 获取行或单元(cell)的值 |
| incr | 增加指定表,行或列的值 |
| list | 列出hbase中存在的所有表 |
| put | 向指向的表单元添加值 |
| tools | 列出hbase所支持的工具 |
| scan | 通过对表的扫描来获取对用的值 |
| status | 返回hbase集群的状态信息 |
| shutdown | 关闭hbase集群(与exit不同) |
| truncate | 重新创建指定表 |
| version | 返回hbase版本信息 |
要注意shutdown与exit之间的不同:shutdown表示关闭hbase服务,必须重新启动hbase才可以恢复,exit只是退出hbase shell,退出之后完全可以重新进入。
hbase使用坐标来定位表中的数据,行健是第一个坐标,下一个坐标是列族。
hbase是一个在线系统,和hadoop mapreduce的紧密结合又赋予它离线访问的功能。
hbase接到命令后存下变化信息或者写入失败异常的抛出,默认情况下。执行写入时会写到两个地方:预写式日志(write-ahead log,也称hlog)和memstore,以保证数据持久化。memstore是内存里的写入缓冲区。客户端在写的过程中不会与底层的hfile直接交互,当menstore写满时,会刷新到硬盘,生成一个新的hfile.hfile是hbase使用的底层存储格式。menstore的大小由hbase-site.xml文件里的系统级属性hbase.hregion.memstore.flush.size来定义。
hbase在读操作上使用了lru缓存机制(blockcache),blockcache设计用来保存从hfile里读入内存的频繁访问的数据,避免硬盘读。每个列族都有自己的blockcache。blockcache中的block是hbase从硬盘完成一次读取的数据单位。block是建立索引的最小数据单位,也是从硬盘读取的最小数据单位。如果主要用于随机查询,小一点的block会好一些,但是会导致索引变大,消耗更多内存,如果主要执行顺序扫描,大一点的block会好一些,block变大索引项变小,因此节省内存。
LRU是Least Recently Used 近期最少使用算法。内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。
数据模型概括:
表(table)———hbase用表来组织数据。表名是字符串(string),由可以在文件系统路径里使用的字符组成。
行(row)———在表里,数据按行存储。行由行健(rowkey)唯一标识。行健没有数据类型,总是视为字节数组byte[].
列族(column family)———–行里的数据按照列族分组,列族也影响到hbase数据的物理存放。因此,它们必须事前定义并且不轻易修改。表中每行拥有相同列族,尽管行不需要在每个列族里存储数据。列族名字是字符串,由可以在文件系统路径里使用的字符组成。(HBase建表是可以添加列族,alter ‘t1’, {NAME => ‘f1’, VERSIONS => 5} 把表disable后alter,然后enable)
列限定符(column qualifier)——–列族里的数据通过列限定符或列来定位。列限定符不必事前定义。列限定符不必在不同行之间保持一致,就像行健一样,列限定符没有数据类型,总是视为字节数组byte[].
单元(cell)——-行健,列族和列限定符一起确定一个单元。存储在单元里的数据称为单元值(value),值也没有数据类型,总是视为字节数组byte[].
时间版本(version)——–单元值有时间版本,时间版本用时间戳标识,是一个long。没有指定时间版本时,当前时间戳作为操作的基本。hbase保留单元值时间版本的数量基于列族进行配置。默认数量是3个。
hbase在表里存储数据使用的是四维坐标系统,依次是:行健,列族,列限定符和时间版本。 hbase按照时间戳降序排列各时间版本,其他映射建按照升序排序。
hbase把数据存放在一个提供单一命名空间的分布式文件系统上。一张表由多个小一点的region组成,托管region的服务器叫做regionserver.单个region大小由配置参数hbase.hregion.max.filesize决定,当一个region大小变得大于该值时,会切分成2个region.
hbase是一种搭建在hadoop上的数据库。依靠hadoop来实现数据访问和数据可靠性。hbase是一种以低延迟为目标的在线系统,而hadoop是一种为吞吐量优化的离线系统。互补可以搭建水平扩展的数据应用。
HBASE中的表示按column family来存储的
建立一个有3个column family的表
create ‘t1’, {NAME => ‘f1’, VERSIONS => 1}, {NAME => ‘f2’, VERSIONS => 1}, {NAME => ‘f3’, VERSIONS => 1}
定义表的时候只需要指定column family的名字,列名在put的时候动态指定
插入数据
下面插入没有指定column的名字
put ‘t1’, ‘r1’, ‘f1’, ‘v1’
put ‘t1’, ‘r2’, ‘f2’, ‘v2’
put ‘t1’, ‘r3’, ‘f3’, ‘v3’
下面插入指定column的名字
put ‘t1’, ‘r4’, ‘f1:c1’, ‘v1’
put ‘t1’, ‘r5’, ‘f2:c2’, ‘v2’
put ‘t1’, ‘r6’, ‘f3:c3’, ‘v3’
hbase(main):245:0> scan ‘t1’
ROW COLUMN+CELL
r1 column=f1:, timestamp=1335407967324, value=v1
r2 column=f2:, timestamp=1335408004559, value=v2
r4 column=f1:c1, timestamp=1335408640777, value=v1
r5 column=f2:c1, timestamp=1335408640822, value=v2
r6 column=f1:c6, timestamp=1335412392258, value=v3
r6 column=f2:c1, timestamp=1335412384739, value=v3
r6 column=f2:c2, timestamp=1335412374797, value=v3
插入多列的数据
put ‘t1’, ‘r7’, ‘f1:c4’, ‘v9’
put ‘t1’, ‘r7’, ‘f2:c3’, ‘v9’
put ‘t1’, ‘r7’, ‘f3:c2’, ‘v9’
手工把memstore写到Hfile中
flush ‘t1’
删除所有CF3的数据
deleteall ‘t1′,’r7’
flush ‘t1’
每次flash都会建一个新的hfile
$ ../bin/hadoop dfs -lsr /hbase/t1
数据时直接存到CF目录下的,每个CF目录下有3到4个Hfile
f1
f1/098a7a13fa53415b8ff7c73d4d69c869
f1/321c6211383f48dd91e058179486587e
f1/9722a9be0d604116882115153e2e86b3
f2
f2/43561825dbde4900af4fb388040c24dd
f2/93a20c69fdec43e8beeed31da8f87b8d
f2/b2b126443bbe4b6892fef3406d6f9597
f3
f3/98352b1b34e242ecac72f5efa8f66963
f3/e76ed1b564784799affa59fea349e00d
f3/f9448a9a381942e7b785e0983a66f006
f3/fca4c36e48934f2f9aaf1a585c237d44
f3都数据虽然都被删除了,由于没有合并文件都存在
手工合并hfile
hbase(main):244:0> compact ‘t1’
0 row(s) in 0.0550 seconds
$ ../bin/hadoop dfs -lsr /hbase/t1
f1
f1/00c05ba881a14ca0bdea55ab509c2327
f2
f2/95fbe85769d64fc4b291cabe73b1ddb2
/f3
f1和f2下就只有一个hfile,f3下面没有hfile因为数据都被删除了
一次只能put一个column
一次只能delete一个column
删除整行,用deleteall
deleteall ‘t1’, ‘r1’
hbase表设计:
hbase表很灵活,可以用字符数组形式存储任何东西。在同一列族里存储相似访问模式的所有东西。
索引建立在keyvalue对象的key部分上,key由行健,列限定符和时间戳按次序组成。高表可能支持你把运算复杂度降到o(1),但是要在原子性上付出代价。
hbase不支持跨行事务,列限定符可以用来存储数据,列族名字的长度影响了通过网络传回客户端的数据大小(在keyvalue对象里),所以尽量简练。
散列支持定长键和更好的数据分布,但是失去排序的好处。设计hbase模式时进行反规范化处理是一种可行的办法。从性能观点看,规范化为写做优化,而反规范化为读做优化。
进入hbase shell console
$HBASE_HOME/bin/hbase shell
如果有kerberos认证,需要事先使用相应的keytab进行一下认证(使用kinit命令),认证成功之后再使用hbase shell进入可以使用whoami命令可查看当前用户
hbase(main)> whoami

表的管理
1)通过list可以列出所有已创建的表(除-ROOT表和.META表(被过滤掉了))
hbase(main)> list
2)创建表,其中t1是表名,f1、f2是t1的列族。hbase中的表至少有一个列族.它们之中,列族直接影响hbase数据存储的物理特性。
# 语法:create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}
# 例如:创建表t1,有两个family name:f1,f2,且版本数均为2
hbase(main)> create ‘t1’,{NAME => ‘f1’, VERSIONS => 2},{NAME => ‘f2’, VERSIONS => 2}

3)删除表
分两步:首先disable,然后drop
例如:删除表t1
hbase(main)> disable ‘t1’
hbase(main)> drop ‘t1’

4)查看表的结构
# 语法:describe(desc) <table> (可以看到这个表的所有默认参数)
# 例如:查看表t1的结构
hbase(main)> describe ‘t1’ / desc ‘t1’

5)修改表结构
修改表结构必须先disable
# 语法:alter ‘t1’, {NAME => ‘f1’}, {NAME => ‘f2’, METHOD => ‘delete’}
# 例如:修改表test1的cf的TTL为180天
hbase(main)> disable ‘test1’
hbase(main)> alter ‘test1′,{NAME=>’body’,TTL=>’15552000′},{NAME=>’meta’, TTL=>’15552000′}
hbase(main)> enable ‘test1’


权限管理
1)分配权限
# 语法 : grant <user> <permissions> <table> <column family> <column qualifier> 参数后面用逗号分隔
# 权限用五个字母表示: “RWXCA”.
# READ(‘R’), WRITE(‘W’), EXEC(‘X’), CREATE(‘C’), ADMIN(‘A’)
# 例如,给用户‘test’分配对表t1有读写的权限,
hbase(main)> grant ‘test’,’RW’,’t1′
2)查看权限
# 语法:user_permission <table>
# 例如,查看表t1的权限列表
hbase(main)> user_permission ‘t1’
3)收回权限
# 与分配权限类似,语法:revoke <user> <table> <column family> <column qualifier>
# 例如,收回test用户在表t1上的权限
hbase(main)> revoke ‘test’,’t1′
表数据的增删改查
1)添加数据
# 语法:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
# 例如:给表t1的添加一行记录:rowkey是rowkey001,family name:f1,column name:col1,value:value01,timestamp:系统默认
hbase(main)> put ‘t1′,’rowkey001′,’f1:col1′,’value01’

用法比较单一。
2)查询数据
a)查询某行记录
# 语法:get <table>,<rowkey>,[<family:column>,….]
# 例如:查询表t1,rowkey001中的f1下的col1的值
hbase(main)> get ‘t1′,’rowkey001’, ‘f1:col1’
# 或者:
hbase(main)> get ‘t1′,’rowkey001′, {COLUMN=>’f1:col1’}
# 查询表t1,rowke002中的f1下的所有列值
hbase(main)> get ‘t1′,’rowkey001’

b)扫描表
# 语法:scan <table>, {COLUMNS => [ <family:column>,…. ], LIMIT => num}
# 另外,还可以添加STARTROW、TIMERANGE和FITLER等高级功能
# 例如:扫描表t1的前5条数据
hbase(main)> scan ‘t1’,{LIMIT=>5}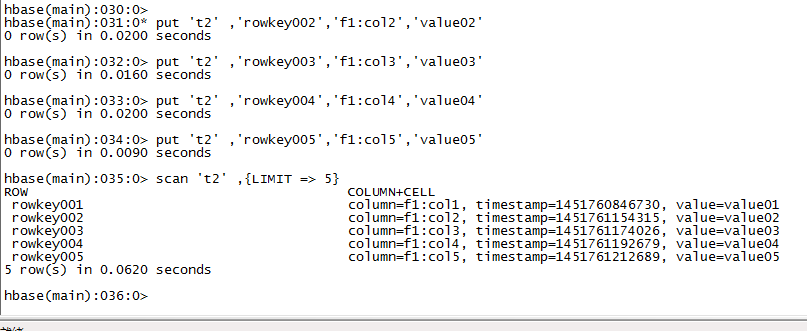
c)查询表中的数据行数
# 语法:count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
# INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
# 例如,查询表t1中的行数,每100条显示一次,缓存区为500
hbase(main)> count ‘t1’, {INTERVAL => 100, CACHE => 500}
3)删除数据
a )删除行中的某个列值
# 语法:delete <table>, <rowkey>, <family:column> , <timestamp>,必须指定列名
# 例如:删除表t1,rowkey001中的f1:col1的数据
hbase(main)> delete ‘t1′,’rowkey001′,’f1:col1’
注:将删除改行f1:col1列所有版本的数据
b )删除行
# 语法:deleteall <table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,删除整行数据
# 例如:删除表t1,rowk001的数据
hbase(main)> deleteall ‘t1′,’rowkey001’
c)删除表中的所有数据
# 语法: truncate <table>
# 其具体过程是:disable table -> drop table -> create table
# 例如:删除表t1的所有数据
hbase(main)> truncate ‘t1’
Region管理
1)移动region
# 语法:move ‘encodeRegionName’, ‘ServerName’
# encodeRegionName指的regioName后面的编码,ServerName指的是master-status的Region Servers列表
# 示例
hbase(main)>move ‘4343995a58be8e5bbc739af1e91cd72d’, ‘db-41.xxx.xxx.org,60020,1390274516739’
2)开启/关闭region
# 语法:balance_switch true|false
hbase(main)> balance_switch
3)手动split
# 语法:split ‘regionName’, ‘splitKey’
4)手动触发major compaction
#语法:
#Compact all regions in a table:
#hbase> major_compact ‘t1’
#Compact an entire region:
#hbase> major_compact ‘r1’
#Compact a single column family within a region:
#hbase> major_compact ‘r1’, ‘c1’
#Compact a single column family within a table:
#hbase> major_compact ‘t1’, ‘c1’
配置管理及节点重启
1)修改hdfs配置
hdfs配置位置:/etc/hadoop/conf
# 同步hdfs配置
cat /home/hadoop/slaves|xargs -i -t scp /etc/hadoop/conf/hdfs-site.xml hadoop@{}:/etc/hadoop/conf/hdfs-site.xml
#关闭:
cat /home/hadoop/slaves|xargs -i -t ssh hadoop@{} “sudo /home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh –config /etc/hadoop/conf stop datanode”
#启动:
cat /home/hadoop/slaves|xargs -i -t ssh hadoop@{} “sudo /home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh –config /etc/hadoop/conf start datanode”
2)修改hbase配置
hbase配置位置:
# 同步hbase配置
cat /home/hadoop/hbase/conf/regionservers|xargs -i -t scp /home/hadoop/hbase/conf/hbase-site.xml hadoop@{}:/home/hadoop/hbase/conf/hbase-site.xml
# graceful重启
cd ~/hbase
bin/graceful_stop.sh –restart –reload –debug inspurXXX.xxx.xxx.org