文章目录
项目源码
https://github.com/a252937166/toutiaocrawler.git
爬虫目标
爬取某一头条号下面所有文章。
爬虫设计思路
爬取方式
动态解析网页方式爬取
之前介绍过使用webdriver的方式爬取网页内容,这样做的话好处非常明显,只需要考虑如何解析网页的element标签就行了,当然弊端也非常明显,就是效率不高。
解析接口方式爬取
没遇到反爬手段逆天的网页,我一般不推荐使用webdriver的方式,作为一名技术人员,始终要把项目性能放到第一位,所以这次的项目我选择使用破解今日头条接口的方式去拿取他们的文章。
解析思路
破解入口
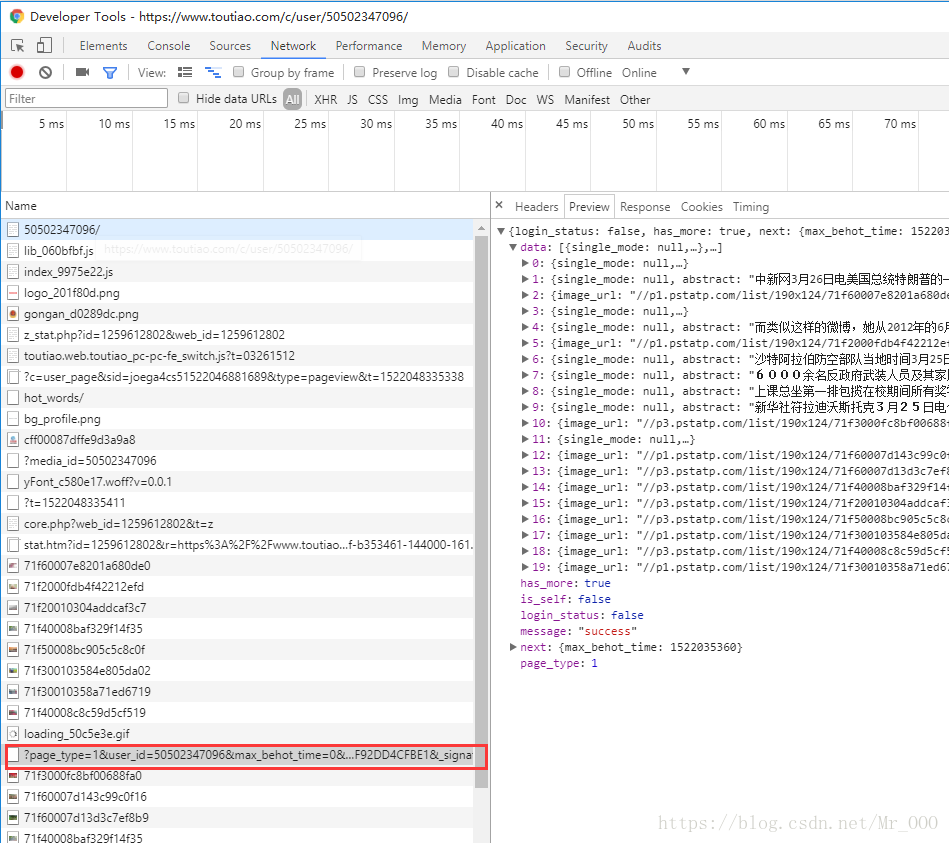
以台海网为例,一般大型平台都会有pc和H5两种网页。
pc:https://www.toutiao.com/c/user/50502347096/#mid=50502347096
 **图(1)**
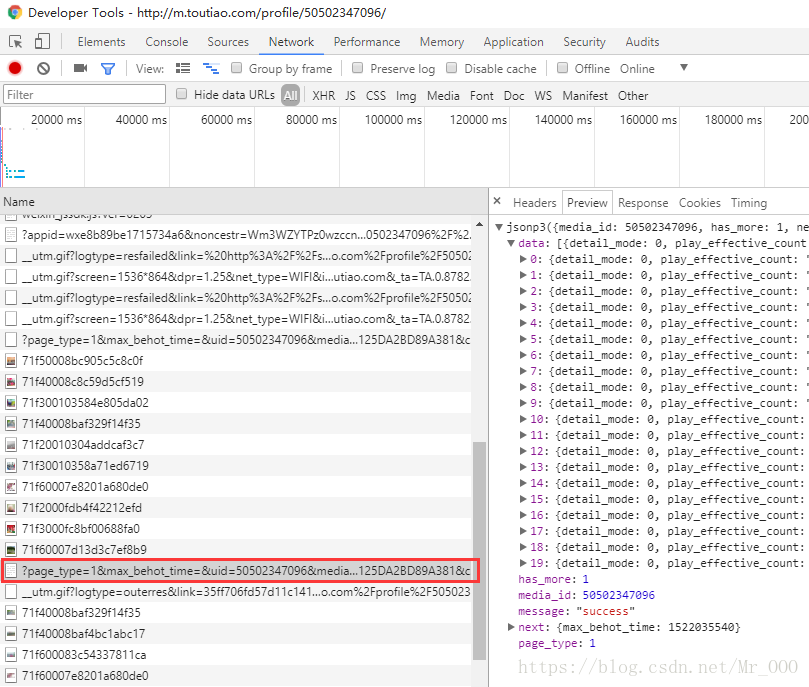
h5:http://m.toutiao.com/profile/50502347096/#mid=50502347096(切换到文章的TAB)
 **图(2)**
由Network的信息可以得到两个文章接口:
pc:
https://www.toutiao.com/c/user/article/?page_type=1&user_id=50502347096&max_behot_time=0&count=20&as=A1B57ACB48A9D4F&cp=5AB8F92DD4CFBE1&_signature=NVHtvxAab.D7OmttJlHb-zVR7a
h5:
https://www.toutiao.com/pgc/ma/?page_type=1&max_behot_time=&uid=50502347096&media_id=50502347096&output=json&is_json=1&count=20&from=user_profile_app&version=2&as=A125DA2BD89A381&cp=5AB81AE3C8116E1&callback=jsonp3
接口对比
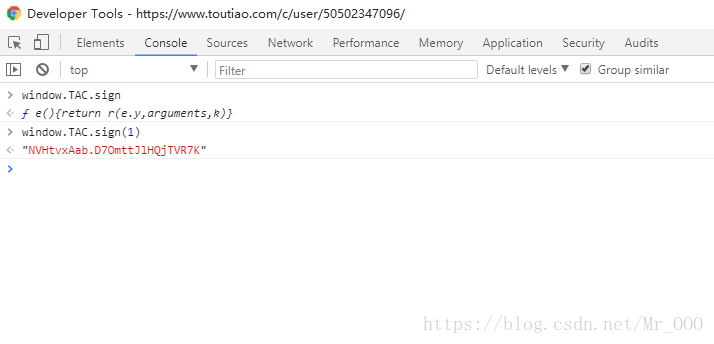
很明显,pc端的接口比h5的接口多一个_signature参数,我私下尝试过破解_signature的生成方法,结果发现异常复杂,我的前端水平根本搞不定,方法是window.TAC.sign,有兴趣的同学可以去试试。
 **图(3)**
无奈只能选择h5的接口了,现在只需要破解as和cp两个参数就行了。
破解加密参数
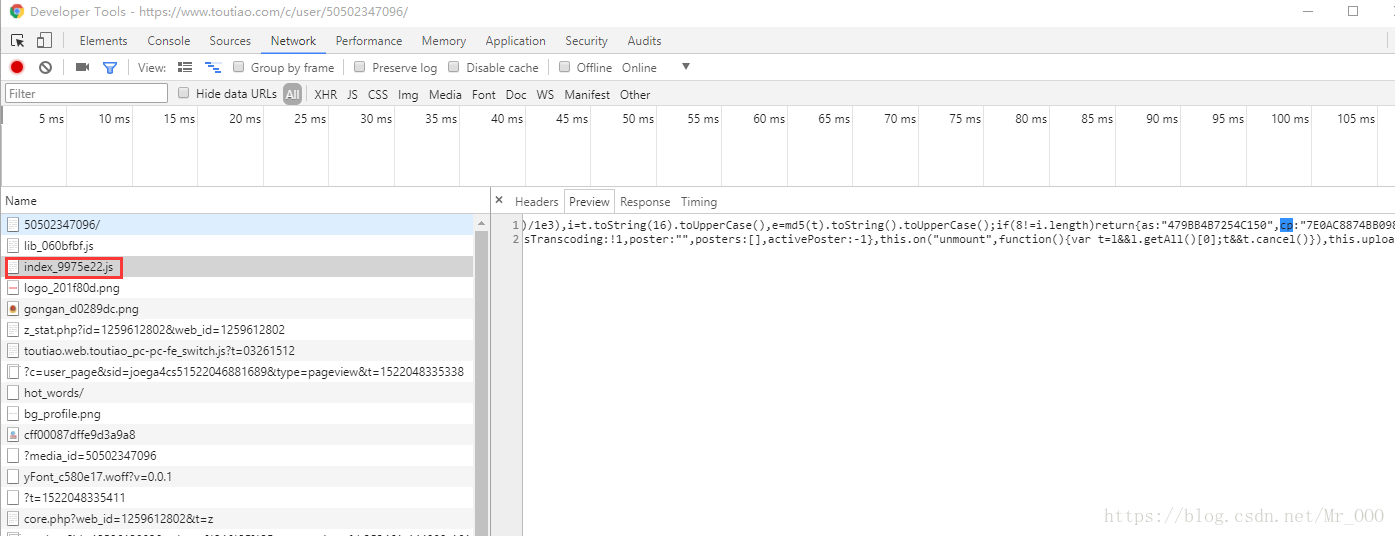
参数生成方式
第一部当然是找参数怎么生成的,很遗憾,这一步没有捷径,只能复制好as和cp,去每一个js文件里面匹配,需要一点耐心。
 **图(4)**
解析js
格式化该方法:
!function(t) {
var i = {};
i.getHoney = function() {
var t = Math.floor((new Date).getTime() / 1e3)
, i = t.toString(16).toUpperCase()
, e = md5(t).toString().toUpperCase();
if (8 != i.length)
return {
as: "479BB4B7254C150",
cp: "7E0AC8874BB0985"
};
for (var s = e.slice(0, 5), o = e.slice(-5), n = "", a = 0; 5 > a; a++)
n += s[a] + i[a];
for (var l = "", r = 0; 5 > r; r++)
l += i[r + 3] + o[r];
return {
as: "A1" + n + i.slice(-3),
cp: i.slice(0, 3) + l + "E1"
}
}
,
t.ascp = i
}(window, document)
不算太难,一个简单的MD5加密方式,转成java方法也很简单:
public static Map<String,String> getAsCp(){
String as = "479BB4B7254C150";
String cp = "7E0AC8874BB0985";
int t = (int) (new Date().getTime()/1000);
String e = Integer.toHexString(t).toUpperCase();
String i = DigestUtils.md5DigestAsHex(String.valueOf(t).getBytes()).toUpperCase();
if (e.length()==8) {
char[] n = i.substring(0,5).toCharArray();
char[] a = i.substring(i.length()-5).toCharArray();
StringBuilder s = new StringBuilder();
StringBuilder r = new StringBuilder();
for (int o = 0; o < 5; o++) {
s.append(n[o]).append(e.substring(o,o+1));
r.append(e.substring(o+3,o+4)).append(a[o]);
}
as = "A1" + s + e.substring(e.length()-3);
cp = e.substring(0,3) + r + "E1";
}
Map<String,String> map = new HashMap<>();
map.put("as",as);
map.put("cp",cp);
return map;
}
分析接口返回值
media_id:该媒体ID
message:是否成功
next.max_behot_time:下一页的请求参数
has_more:是否有下一页
data.article_url:文章的html地址
其他参数都不重要了,这里并没有直接返回文章的内容,下一步就是去原文地址爬取文章内容了。
解析原文地址
基本是个静态网页,直接提取标签里面的内容就行了。
java项目解析
基本功能
为了方便,我使用spring boot框架,设计成了一个web项目,以访问接口的方式启动或者停止爬虫。
队列和线程池
因为是接口的方式启动爬虫,所以不可能等10多万个爬虫任务结束之后再返回成功,只能异步执行任务,所以需要线程池。
光有线程池还不够,几十万甚至更多的任务全部甩给线程池,显然不是一个好的选择。所以这里就需要java的Queue,我选择的是LinkedBlockingDeque,不过最后还是没用到双端的特性,所以使用LinkedBlockingQueue是一样的,把所有需要爬取的任务先放入Queue队列中,开始爬取的时候再从里面拿去地址,这样就可简单的解决高并发的问题。
如果任务量特别大,而且有对详细日志的需求,可以选择换成kafka。
操作界面——swagger2
使用postman发送请求还是不太方便,还要填地址之类的,我考虑有个前端界面来操作就最好了,但是前端水平有限,不想花太多时间写,所以选择了集成swagger2。
打开http://127.0.0.1:9091/swagger-ui.html#/
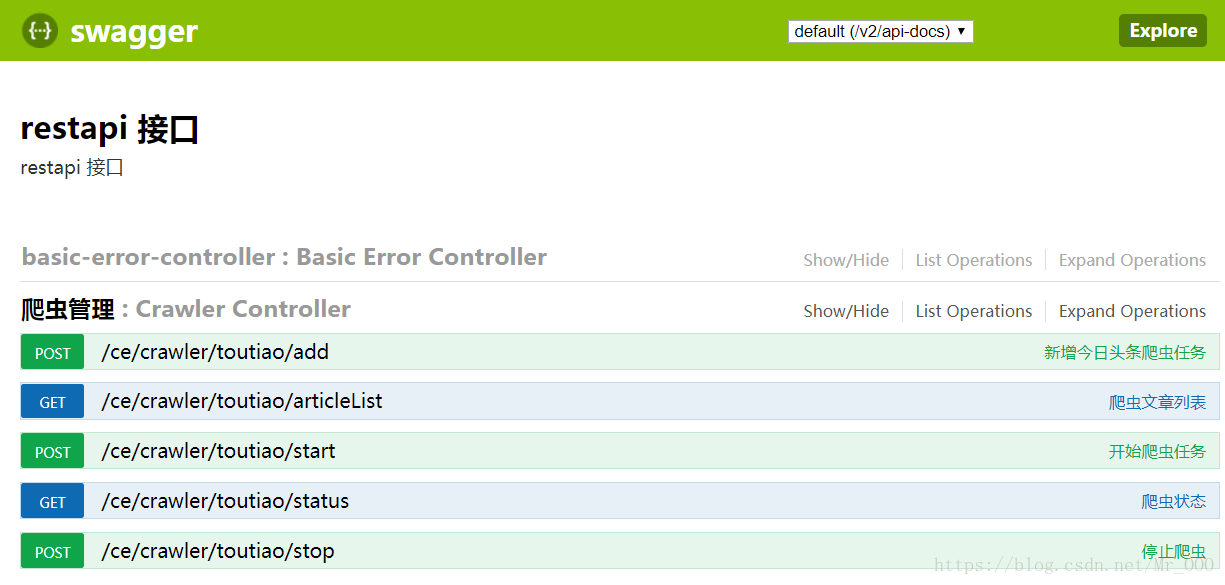 **图(5)** 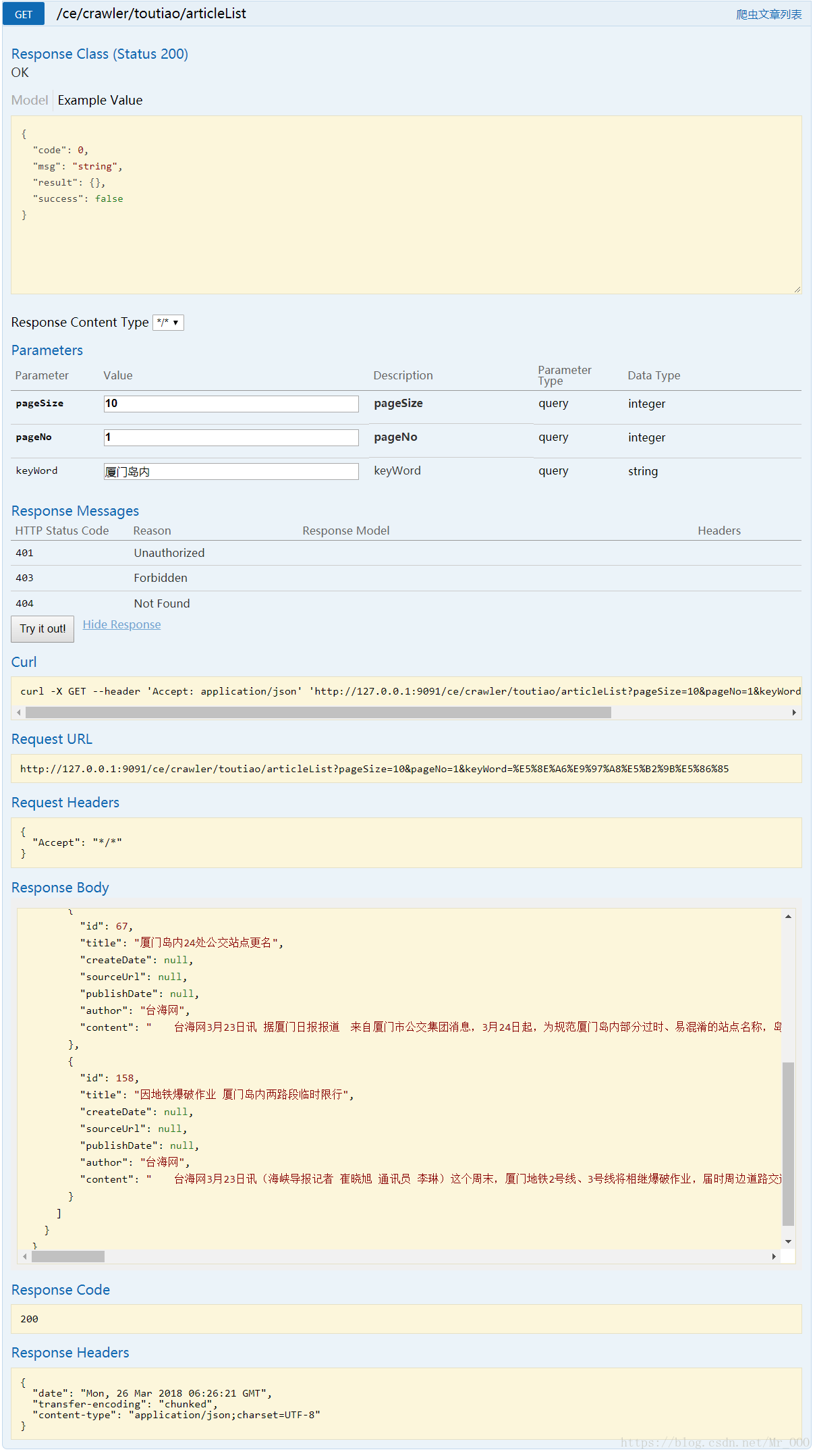 **图(6)**
一看就知道怎么用了,我就不多介绍了,有兴趣的同学,可以根据这五个接口,写一个前端界面,一个针对头条号的爬虫就算完成了。
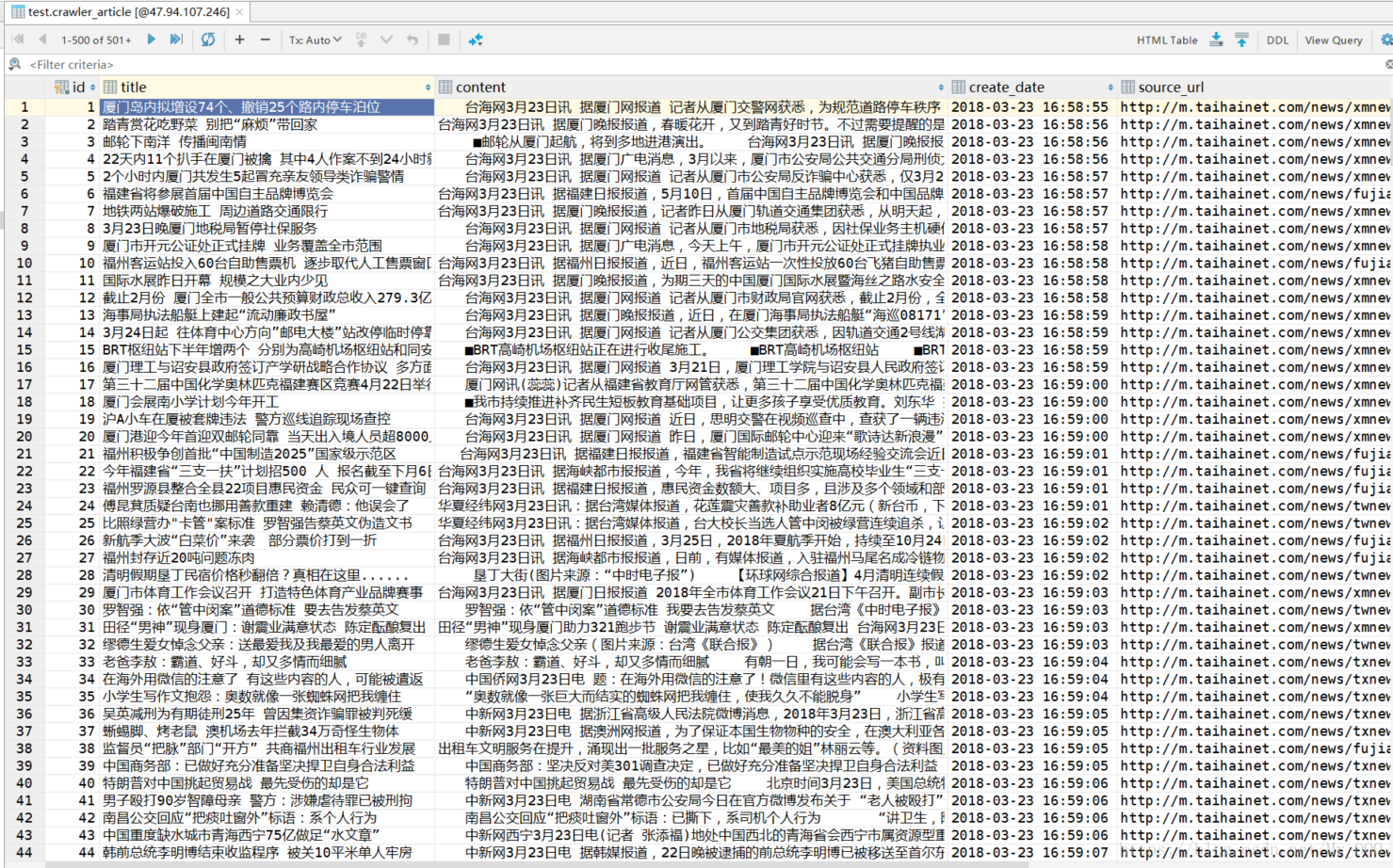 **图(7)**
总结
爬虫最难的地方其实并不在代码上,而在于对爬取网页的分析上,比如制定爬取方式,攻破对方的反爬手段等等,需要一些耐心和分析能力,所谓熟能生巧,最主要的还是要多尝试,累计经验。
补充
经网友提示发现,每个mid下的内容页的结构方式略有不同,本文中的mid的内容页是静态页面,所以使用Jsoup解析,另外有些mid,比如1558737777313793(AI财经社),它的内容页是动态页面,我使用的是正则匹配获取对应数据,示例在dev1.0分支上,大家可以借鉴一下,掌握这两种解析方式,解析其他mid都大同小异了。
同系列文章
java爬虫系列(一)——爬虫入门
java爬虫系列(二)——爬取动态网页
java爬虫系列(三)——漫画网站爬取实战
java爬虫系列(四)——动态网页爬虫升级版