CQRS体系结构模式
本文将对CQRS(Command Query Responsibility Segregation,命令查询职责分离)模式做一个相对全面的介绍。可以这么说,CQRS打破了经典的领域驱动设计实践,在应用CQRS的整个过程中,你将会以另一种不同的角度去考虑问题并寻求解决方案。比如,CQRS是事件驱动的体系结构,事件是如何产生如何分发又是如何处理的?事件驱动的体系结构适用于哪些类型的应用系统?CQRS中的仓储,与经典DDD中的仓储又有何异同?等等这些问题,都给我们留下了无限的思考空间。
背景
在讲CQRS之前,我们先了解一下CQS(Command-Query Separation,命令查询)模式。名字上看,两者没什么差别,然而CQRS应该说是,在DDD的实践中引入CQS理论而出现的一种体系结构模式。CQS模式最早由著名软件大师Bertrand Meyer(Eiffel语言之父,面向对象开-闭原则OCP提出者)提出,他认为,对象的行为仅有两种:命令和查询,不存在第三种情况。用他自己的话来说,就是:“提问永远无法改变答案”。根据CQS,任何方法都可以拆分为命令和查询两个部分。比如,下面的代码:
隐藏行号 复制代码 ? 代码
private int i = 0;
private int Add(int factor)
{i += factor;
return i;
}
可以替换为:
隐藏行号 复制代码 ? 代码
private void AddCommand(int factor)
{i += factor;
}
private int QueryValue()
{return i;
}
当命令和查询被分离的时候,我们将会有更多的机会去把握整个事情的细节。比如我们可以对系统的“命令”部分和“查询”部分分别采用不同的技术架构,以使得系统具有更好的扩展性,并获得更好的性能。在DDD领域中,Greg Young和Eric Evans根据Bertrand Meyer的CQS模式,结合实际项目经验,总结了CQRS体系结构模式。
结构
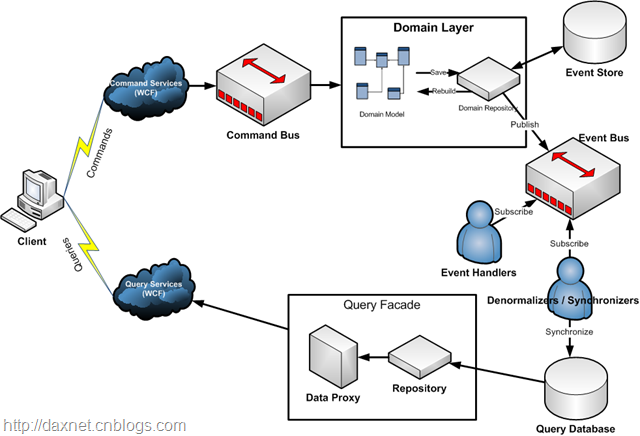
整个系统结构被分为两个部分:命令部分和查询部分。我根据自己的体会,描绘了CQRS的体系结构简图如下,供大家参考。在讨论CQRS体系结构之前,我们有必要事先弄清楚这样几个概念:对象状态、事件溯源(Event Sourcing)、快照(Snapshots)以及事件存储(Event Store)。讨论的过程中你会发现,很多概念与我们之前对经典DDD的理解相比,有着很大的不同。
对象状态
这是一个大家耳熟能详的概念了。什么是对象状态?在被面向对象编程(OOP)“熏陶”了很久的朋友,一听到“对象状态”,马上想到了一对对的getter/setter属性。尤其是.NET程序员,在C# 3.0及以后版本中,引入了Auto-Property的概念,于是,对象的属性就很容易地成为了对象状态的代名词。在这里,我们应该看到问题的本质,即使是Auto-Property,它也无非是对对象字段的一种封装,只不过在使用Auto-Property的时候,C#编译器会在后台创建一个私有的、匿名的字段(field),而Property则成为了从外部访问该字段的唯一途径。换句话说,对象的状态是保存在这些字段里的,对象属性无非是访问字段的facade。在这里澄清这样一个事实,就是为了当你继续阅读本文的时候,不至于对事件溯源(Event Sourcing)的某些具体实现感到困惑。在Event Sourcing的具体实现中,领域对象不再需要具备公有的属性,至少外界无法通过公有属性改变对象状态(即setter被定义为private,甚至没有setter)。这与经典的DDD设计相比,无疑是一个重大改变。例如,现在我要改变某个Customer的状态,如果采用经典DDD的实现方式,就是:
隐藏行号 复制代码 ? 代码
[TestMethod]
public void TestChangeCustomerName()
{IocContainer c = IocContainer.GetIocContainer();
using (IRepositoryTransactionContext ctx = c.GetService<IRepositoryTransactionContext>())
{IRepository<Customer> customerRepository = ctx.GetRepository<Customer>();
Customer customer = customerRepository
.Get(Specification<Customer>
.Eval(p=>p.FirstName.Equals("sunny") && p.LastName.Equals("chen")));
// Here we use the properties directly to update the state
customer.FirstName = "dax";
customer.LastName = "net";
customerRepository.Update(customer);
ctx.Commit();
}
}
现在,很多ORM工具都需要聚合根具有public的getter/setter,这本身就是技术实现上的一种约束,比如某些ORM工具会使用reflection,通过读写对象的property来改变对象状态。为什么ORM工具要选择properties,而不是fields?因为这些框架不希望自己的介入会改变对象对其状态的封装级别(也就是访问限制)。在引入CQRS后,ORM已经没有太多的用武之地了,当然从技术选型的角度看,你仍然可以选择ORM,但就像关系型数据库那样,它已经显得没那么重要了。
事件溯源(Event Sourcing)
在某些情况下,我们不仅需要知道对象的当前状态是什么,而且还需要知道,对象经历了哪些路程,才获得了当前这样的状态。Martin Fowler在介绍Event Sourcing的时候,举了个邮包跟踪(Package Tracking)的例子。在经典的DDD实践中,我们只能通过Shipment.Location来获得邮包的当前位置,却没办法获得邮包经历过哪些地址而最终到达当前的地址。
为了使我们的业务系统具有记录对象历史状态的能力,我们使用事件驱动的领域模型来实现我们的业务系统。简而言之,就是对模型对象状态的修改,仅允许通过事件的途径实现,外界无法通过任何其他途径修改对象的状态。那么,记录对象的状态修改历史,就只需要记录事件的类型以及发生顺序即可,因为对象的状态是由领域事件更改的。于是,也就能理解上面所讲的为什么在Event Sourcing的实现中,领域对象将不再具有公有属性,或者说,至少不再具有公有的setter属性。
当对象的状态被修改后,我们可能希望将对象保存到持久化机制,这一点与经典的DDD实践上的考虑是类似的。而与之不同的是,现在我们保存的已不再是某个领域对象在某个时间点上的状态,而是促使对象将其状态改变到当前点的一系列事件。由此,仓储(Repository)的实现需要发生变化,它需要有保存领域事件的功能,同时还需要有通过一系列保存的事件数据,重建聚合根的能力。看到这里,你就知道为什么会有Event Sourcing这个概念了:所谓Event Sourcing,就是“通过事件追溯对象状态的起源(与经过)”,它允许你通过记录下来的事件,将你的领域模型恢复到之前任意一个时间点。你可能会兴奋地说:我的领域模型开始支持事件回放与模型重建了!
Event Sourcing让我们“透过现象看本质”,使我们更进一步地了解到“对象持久化”的具体含义,其实也就是对象状态的持久化。只不过,Event Sourcing并不是直接保存了对象的状态,而是一系列引起状态变化的领域事件。
仍然以上面的更改客户姓名为例,在引入领域事件与Event Sourcing之后,整个模型的结构发生了变化,以下是相关代码,仅供参考。
隐藏行号 复制代码 ? 代码
[Serializable]
public partial class CustomerCreatedEvent : DomainEvent
{
public string UserName { get; set; }
public string Password { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime DayOfBirth { get; set; }
}
[Serializable]
public partial class ChangeNameEvent : DomainEvent
{
public string FirstName{get;set;}
public string LastName{get;set;}
}
public partial class Customer : SourcedAggregationRoot
{
private DateTime dayOfBirth;
private string userName;
private string password;
private string firstName;
private string lastName;
public Customer(string userName, string password,
string firstName, string lastName, DateTime dayOfBirth)
{this.RaiseEvent<CustomerCreatedEvent>(new CustomerCreatedEvent
{
DayOfBirth = dayOfBirth,
FirstName = firstName,
LastName = lastName,
UserName = userName,
Password = password
});
}
public void ChangeName(string firstName, string lastName)
{this.RaiseEvent<ChangeNameEvent>(new ChangeNameEvent
{
FirstName = firstName,
LastName = lastName
});
}
// Handles the ChangeNameEvent by using Reflection
[Handles(typeof(ChangeNameEvent))]
private void DoChangeName(ChangeNameEvent e)
{this.firstName = e.FirstName;
this.lastName = e.LastName;
}
// Handles the CustomerCreatedEvent by using Reflection
[Handles(typeof(CustomerCreatedEvent))]
private void DoCreateCustomer(CustomerCreatedEvent e)
{this.firstName = e.FirstName;
this.lastName = e.LastName;
this.userName = e.UserName;
this.password = e.Password;
this.dayOfBirth = e.DayOfBirth;
}
}
上面的代码中定义了两个Domain Event:CustomerCreatedEvent和ChangeNameEvent。在Customer聚合根的构造函数中,直接触发CustomerCreatedEvent以便该事件的订阅者对Customer对象进行初始化;而在Customer聚合根的ChangeName方法中,则直接触发ChangeNameEvent以便该事件的订阅者对Customer的first name和last name作修改。Customer的基类SourcedAggregationRoot则在领域事件被触发的时候通过Reflection机制获得内部的事件处理函数,并调用该函数完成事件处理。在上面的例子中,也就是DoChangeName和DoCreateCustomer这两个方法。在这里需要注意的是,类似DoChangeName和DoCreateCustomer这样的事件处理函数中,仅允许包含对对象状态的设置逻辑。因为如果引入其它操作的话,很难保证通过这些操作,对象的状态不会发生改变。
深入思考上面的设计会发现一个问题,也就是当模型对象变得非常庞大,或者随着时间的推移,领域事件将变得越来越多,于是通过Event Sourcing来重建聚合根的过程也会变得越来越耗时,因为每一次从建都需要从最早发生的事件开始。为了解决这个问题,Event Sourcing引入了“快照(Snapshots)”。
快照(Snapshots)
Snapshot的设计其实很简单。标准的CQRS实现中,采用“每产生N个领域事件,则对对象做一次Snapshot”的简单规则。设计人员其实可以根据自己的实际情况定义N的取值,甚至可以选用特定的Snapshot规则,以提高对象重建的效率。当需要通过仓储获得某一个聚合根实体时,仓储会首先从Snapshot Store中获得最近一次的快照,然后再在由此快照还原的聚合根实体上逐个应用快照之后所产生的领域事件,由此大大加速了对象重建的过程。快照通常采用GoF Memento模式实现。请注意:CQRS引入快照的概念仅仅是为了解决对象重建的效率问题,它并不能替代领域事件所能表述的含义。换句话说,即使引入快照,也不能表示我们能够将快照之前的所有事件从事件存储(Event Store)中删除。因为,我们记录领域事件的目的,是为了Event Sourcing,而不是Snapshots。

事件存储(Event Store)
通常,事件存储是一个关系型数据库,用来保存引起领域对象状态更改的所有领域事件。如上所述,在CQRS结构的系统实现中,数据库已经不再直接保存对象的当前状态了,保存的只是引起对象状态发生变化的领域事件。于是,数据库的数据结构非常单一,就是单纯的领域事件数据。事件数据的写入、读取都变得非常简单高速,根本无需ORM的介入,直接使用SQL或者存储过程操作事件存储即可,既简单又高效。读到这里,你会发现,虽然系统是用的一个称之为Event Store的机制保存了领域事件,但这个Event Store已经成为了整个系统数据存储的核心。更进一步考虑,Event Store中的事件数据是在仓储执行“保存”操作时,从领域模型中收集并写入的,也就意味着,最新的、最真实的数据仍然存在于领域模型中,正好符合DDD面向领域的思想,同时也引出了另一深层次的考虑:In Memory Domain!
回到结构
在完成对“对象状态”、“事件溯源(Event Sourcing)”、“快照(Snapshots)”以及“事件存储(Event Store)”的讨论后,我们再来看整个CQRS的结构,这样就显得更加清楚。上文【CQRS体系结构模式】图中,用户操作被分为命令部分(图中上半部分)和查询部分(图中下半部分)。
- 用户与领域层的交互,是以命令的方式进行的:用户通过Command Service向领域模型发送命令。Command Service通常被实现为.NET WCF Service。Command Bus在接收到命令后,将命令指派到命令执行器由其负责执行(可以参考GoF Command模式。TBD: 可以选择更符合CQRS实现的其它途径)。命令执行器在执行命令时,通过领域事件更改对象状态,并通过仓储保存领域对象。而仓储并非直接将对象状态保存到外部持久化机制,而仅仅是从领域对象中获得已产生的一系列领域事件,并将这些事件保存到Event Store,同时将事件发布到事件总线Event Bus
- Event Handler可以订阅Event Bus中的事件,并在事件发生时作相关处理。上文在讨论服务的时候,有个例子就是利用基础结构层服务发送SMS消息,在CQRS的体系结构中,我们完全可以在此订阅Warehouse Transferred事件,并调用基础结构层服务发送SMS消息。Domain Model完全不知道自己的内部事件被触发后,会出现什么情况,而Event Handler则会处理这些情况(Domain Model与基础结构层完全解耦)
- 在Event Handler中,有一种特殊的Event Handler,称之为Synchronizer或者Denormalizer,其作用就是为了同步“Query Database”。Query Database是为查询提供数据源的存储机制,用户在UI上看到的查询数据均来源于此数据库。因此,CQRS不仅分离了用户操作,而且分离了数据源,这样做的一个最大的优点就是,设计人员可以根据UI的需求来配置和优化Query Database,例如,可以将Query Database设计为一张数据表对应一个UI界面,于是,用户查询变得非常灵活高效。这里也可以使用DDD中的Repository结合ORM实现数据读取,与处于Domain Layer中的Repository不同,这个Repository就是DDD中所提到的经典型仓储了,你可以灵活地使用规约模式。当然,你也可以不使用ORM而直接SQL甚至No SQL,一切取决于用户需求与技术选型。我们还可以根据需要,对Synchronizer和Denormalizer的实现采用缓存,比如,对于无需实时更新的内容,可以每捕获N个事件同步一次Query Database,或者当有客户端query请求时,再做一次同步,这也是提高效率的一种有效方法
- 用户UI通过Data Proxy获得查询结果数据,WCF将数据以DTO的形式发送给客户端
总结
本文介绍了CQRS模式的基本结构,并对其中一些重要概念作了注释,也是我在实践和思考当中总结出来的内容(PS:转载请注明出处)。学习过DDD而刚刚开始CQRS的朋友,在阅读一些资料的时候势必会感到疑惑,希望本文能够帮助到这些朋友。比如最开始阅读的时候,我也不知道为什么一定要通过领域事件去更改对象状态,而不是在对象状态变更的时候,去触发领域事件,因为当时我仍然希望能够在Domain Model中方便地使用getter/setter,我当时也希望能够让Domain Model同时适应于经典DDD和CQRS架构。在经过多次尝试后发现,这种做法是不合理、不可取的,也正如Udi Dahan所说:CQRS是一种模式,既然是模式,就是用来解决特定问题的。
还是一句老话:视需求而定。不要因为CQRS所以CQRS。虽然可以很大程度地提升系统性能,虽然可以使系统具有auditing的能力,虽然可以实现Domain-Centralized,虽然可以让数据存储变得更加简单,虽然给我们提供了很多技术选型的机会,但是,CQRS也有很多不足点,比如结构实现较繁杂,数据同步稳定性难以得到保证,事件溯源(Event Sourcing)出错时,模型对象状态的恢复等等。还是引用Udi Dahan的一句话:简单,但不容易!