1 排序二叉树
排序二叉树是一种特殊结构的二叉树,可以非常方便地对树中所有节点进行排序和检索。 排序二叉树要么是一棵空二叉树,要么是具有下列性质的二叉树: • 若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值; • 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值; • 它的左、右子树也分别为排序二叉树。 下图显示了一棵排序二叉树:
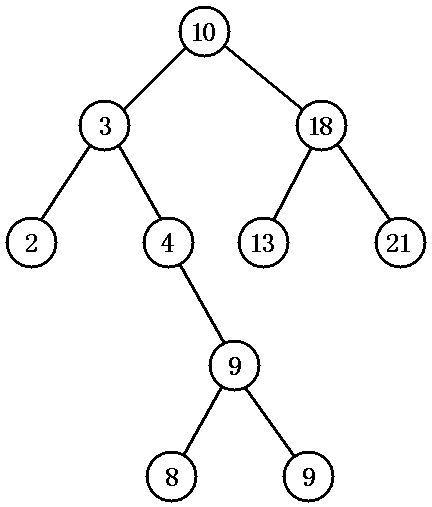
对排序二叉树,若按中序遍历就可以得到由小到大的有序序列。中序遍历得: {2,3,4,8,9,9,10,13,15,18} 排序二叉树虽然可以快速检索,但在最坏的情况下:如果插入的节点集本身就是有序的,要么是由小到大排列,要么是由大到小排列,那么最后得到的排序二叉树将变成链表:所有节点只有左节点(如果插入节点集本身是大到小排列);或所有节点只有右节点(如果插入节点集本身是小到大排列)。在这种情况下,排序二叉树就变成了普通链表,其检索效率就会很差。
2 红黑树
《算法导论》关于红黑树的定义:
正如在CLRS中定义的那样(CLRS指的是就是算法导论这本书《Introduction to Algorithms》,CLRS是该书作者Cormen, Leiserson, Rivest and Stein的首字母缩写),一棵红黑树是指一棵满足下述性质的二叉搜索树(BST, binary search tree): 1. 每个结点或者为黑色或者为红色。 2. 根结点为黑色。 3. 每个叶结点(实际上就是NULL指针)都是黑色的。 4. 如果一个结点是红色的,那么它的两个子节点都是黑色的(也就是说,不能有两个相邻的红色结点)。 5. 对于每个结点,从该结点到其所有子孙叶结点的路径中所包含的黑色结点数量必须相同。
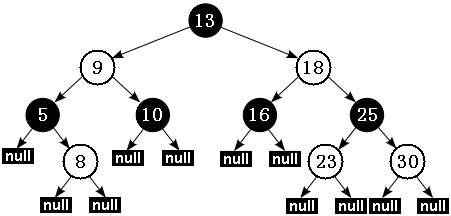
数据项只能存储在内部结点中(internal node)。我们所指的”叶结点”在其父结点中可能仅仅用一个NULL指针表示,但是将它也看作一个实际的结点有助于描述红黑树的插入与删除算法,叶结点一律为黑色。 定义详解: 根据性质 5:红黑树从根节点到每个叶子节点的路径都包含相同数量的黑色节点,因此从根节点到叶子节点的路径中包含的黑色节点数被称为树的“黑色高度(black-height)”。 性质 4 则保证了从根节点到叶子节点的最长路径的长度不会超过任何其他路径的两倍。假如有一棵黑色高度为 3 的红黑树:从根节点到叶节点的最短路径长度是 2,该路径上全是黑色节点(黑节点 – 黑节点 – 黑节点)。最长路径也只可能为 4,在每个黑色节点之间插入一个红色节点(黑节点 – 红节点 – 黑节点 – 红节点 – 黑节点),性质 4 保证绝不可能插入更多的红色节点。由此可见,红黑树中最长路径就是一条红黑交替的路径。 根据定义我们做如下练习: –不符合定义的一颗非红黑树:  红黑树的这5个性质中,第3点是比较难理解的,但它却非常有必要。我们看图1中的左边这张图,如果不使用黑哨兵,它完全满足红黑树性质,结点50到两个叶结点8和叶结点82路径上的黑色结点数都为2个。但如果加入黑哨兵后(如图1右图中的小黑圆点),叶结点的个数变为8个黑哨兵,根结点50到这8个叶结点路径上的黑高度就不一样了,所以它并不是一棵红黑树。 -两颗正确的红黑树:
红黑树的这5个性质中,第3点是比较难理解的,但它却非常有必要。我们看图1中的左边这张图,如果不使用黑哨兵,它完全满足红黑树性质,结点50到两个叶结点8和叶结点82路径上的黑色结点数都为2个。但如果加入黑哨兵后(如图1右图中的小黑圆点),叶结点的个数变为8个黑哨兵,根结点50到这8个叶结点路径上的黑高度就不一样了,所以它并不是一棵红黑树。 -两颗正确的红黑树: 
 定理:
定理:
一棵拥有n个内部结点的红黑树的树高h<=2log(n+1)
由此我们可以得出结论:对于给定的黑色高度为 N 的红黑树,从根到叶子节点的最短路径长度为 N-1,最长路径长度为 2 * (N-1)。 提示:排序二叉树的深度直接影响了检索的性能,正如前面指出,当插入节点本身就是由小到大排列时,排序二叉树将变成一个链表,这种排序二叉树的检索性能最低:N 个节点的二叉树深度就是 N-1。 红黑树通过上面这种限制来保证它大致是平衡的——因为红黑树的高度不会无限增高,这样保证红黑树在最坏情况下都是高效的,不会出现普通排序二叉树的情况。 由于红黑树只是一个特殊的排序二叉树,因此对红黑树上的只读操作与普通排序二叉树上的只读操作完全相同,只是红黑树保持了大致平衡,因此检索性能比排序二叉树要好很多。 但在红黑树上进行插入操作和删除操作会导致树不再符合红黑树的特征,因此插入操作和删除操作都需要进行一定的维护,以保证插入节点、删除节点后的树依然是红黑树。
3 红黑树和AVL树的比较
1.
红黑树并不追求“完全平衡”——它只要求部分地达到平衡要求,降低了对旋转的要求,从而提高了性能。 红黑树能够以
O(log2 n) 的时间复杂度进行搜索、插入、删除操作。此外,由于它的设计,任何不平衡都会在三次旋转之内解决。当然,还有一些更好的,但实现起来更复杂的数据结构,能够做到一步旋转之内达到平衡,但红黑树能够给我们一个比较“便宜”的解决方案。
红黑树的算法时间复杂度和AVL相同,但统计性能比AVL树更高。 当然,红黑树并不适应所有应用树的领域。如果数据基本上是静态的,那么让他们待在他们能够插入,并且不影响平衡的地方会具有更好的性能。如果数据完全是静态的,做一个哈希表,性能可能会更好一些。
红黑树是一个更高效的检索二叉树,因此常常用来实现关联数组。典型地,JDK 提供的集合类 TreeMap 本身就是一个红黑树的实现。
IBM DevelopWorks 上一篇文章讲解非常好,供参考。 TreeMap 和 TreeSet 是 Java Collection Framework 的两个重要成员,其中 TreeMap 是 Map 接口的常用实现类,而 TreeSet 是 Set 接口的常用实现类。虽然 HashMap 和 HashSet 实现的接口规范不同,但 TreeSet 底层是通过 TreeMap 来实现的,因此二者的实现方式完全一样。而 TreeMap 的实现就是红黑树算法。 对于 TreeMap 而言,由于它底层采用一棵“红黑树”来保存集合中的 Entry,这意味这 TreeMap 添加元素、取出元素的性能都比 HashMap 低:当 TreeMap 添加元素时,需要通过循环找到新增 Entry 的插入位置,因此比较耗性能;当从 TreeMap 中取出元素时,需要通过循环才能找到合适的 Entry,也比较耗性能。 但 TreeMap、TreeSet 比 HashMap、HashSet 的优势在于:TreeMap 中的所有 Entry 总是按 key 根据指定排序规则保持有序状态,TreeSet 中所有元素总是根据指定排序规则保持有序状态。 2
AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个儿子子树的高度最大差别为一,所以它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下都是O(log n)。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。 引入二叉树的目的是为了提高二叉树的搜索的效率,减少树的平均搜索长度.为此,就必须每向二叉树插入一个结点时调整树的结构,使得二叉树搜索保持平衡,从而可能降低树的高度,减少的平均树的搜索长度.
AVL树的定义:
一棵AVL树满足以下的条件: 1>它的左子树和右子树都是AVL树 2>左子树和右子树的高度差不能超过1
性质:
1>一棵n个结点的AVL树的其高度保持在0(log2(n)),不会超过3/2log2(n+1) 2>一棵n个结点的AVL树的平均搜索长度保持在0(log2(n)). 3>一棵n个结点的AVL树删除一个结点做平衡化旋转所需要的时间为0(log2(n)).
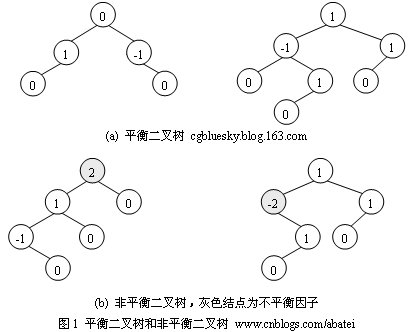
为了保证平衡,AVL树中的每个结点都有一个平衡因子(balance factor,以下用BF表示),它表示这个结点的左、右子树的高度差,也就是左子树的高度减去右子树的高度的结果值。AVL树上所有结点的BF值只能是-1、0、1。反之,只要二叉树上一个结点的BF的绝对值大于1,则该二叉树就不是平衡二叉树。下图演示了平衡二叉树和非平衡二叉树。
 从1这点来看红黑树是牺牲了严格的高度平衡的优越条件为代价红黑树能够以O(log2 n)的时间复杂度进行搜索、插入、删除操作。此外,由于它的设计,任何不平衡都会在三次旋转之内解决。当然,还有一些更好的,但实现起来更复杂的数据结构能够做到一步旋转之内达到平衡,但红黑树能够给我们一个比较“便宜”的解决方案。红黑树的算法时间复杂度和AVL相同,但统计性能比AVL树更高
从1这点来看红黑树是牺牲了严格的高度平衡的优越条件为代价红黑树能够以O(log2 n)的时间复杂度进行搜索、插入、删除操作。此外,由于它的设计,任何不平衡都会在三次旋转之内解决。当然,还有一些更好的,但实现起来更复杂的数据结构能够做到一步旋转之内达到平衡,但红黑树能够给我们一个比较“便宜”的解决方案。红黑树的算法时间复杂度和AVL相同,但统计性能比AVL树更高