Aggregate
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果,类似sql语句中的 count(*)
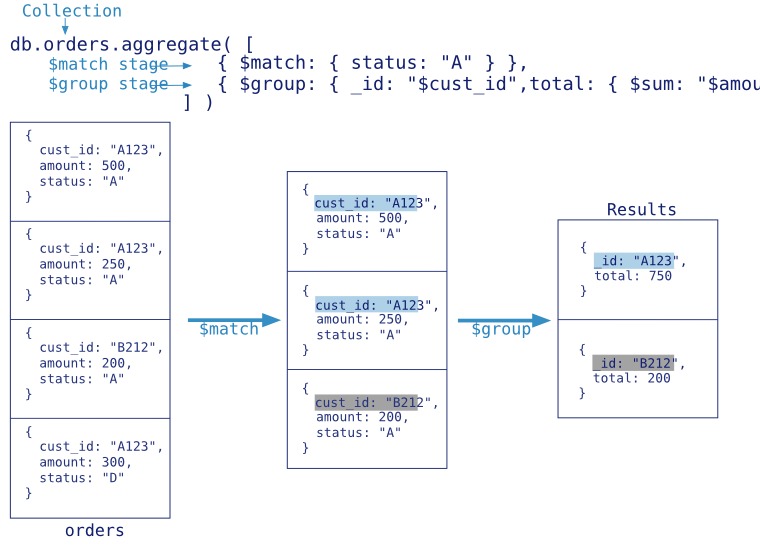
语法如下:
db.collection.aggregate()
db.collection.aggregate(pipeline,options)
db.runCommand({
aggregate: “<collection>”,
pipeline: [ <stage>, <…> ],
explain: <boolean>,
allowDiskUse: <boolean>,
cursor: <document>
})
在使用aggregate实现聚合操作之前,我们首先来认识下几个常用的聚合操作符。
$project::可以对结果集中的键 重命名,控制键是否显示,对列进行计算。
$match: 过滤结果集,只输出符合条件的文档。
$skip: 在显示结果的时候跳过前几行,并返回余下的文档。
$sort: 对即将显示的结果集排序
$limit: 控制结果集的大小
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$geoNear:输出接近某一地理位置的有序文档。
$group: 分组,聚合,求和,平均数,最大值,最小值,第一个,最后一个,等
表达式 描述 实例
$sum 计算总和 db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$sum : “$likes”}}}])
$avg 计算平均值 db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$avg : “$likes”}}}])
$min 获取集合中所有文档对应值得最小值 db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$min : “$likes”}}}])
$max 获取集合中所有文档对应值得最大值 db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$max : “$likes”}}}])
$push 在结果文档中插入值到一个数组中 db.mycol.aggregate([{$group : {_id : “$by_user”, url : {$push: “$url”}}}])
$addToSet在结果文档中插入值到一个数组中,但不创建副本 db.mycol.aggregate([{$group : {_id : “$by_user”, url : {$addToSet : “$url”}}}])
$first 根据资源文档的排序获取第一个文档数据 db.mycol.aggregate([{$group : {_id : “$by_user”, first_url : {$first : “$url”}}}])
$last 根据资源文档的排序获取最后一个文档数据 db.mycol.aggregate([{$group : {_id : “$by_user”, last_url : {$last : “$url”}}}])
实例:
db.createCollection(“emp”)
db.emp.insert({_id:1,”ename”:”tom”,”age”:25,”department”:”Sales”,”salary”:6000})
db.emp.insert({_id:2,”ename”:”eric”,”age”:24,”department”:”HR”,”salary”:4500})
db.emp.insert({_id:3,”ename”:”robin”,”age”:30,”department”:”Sales”,”salary”:8000})
db.emp.insert({_id:4,”ename”:”jack”,”age”:28,”department”:”Development”,”salary”:8000})
db.emp.insert({_id:5,”ename”:”Mark”,”age”:22,”department”:”Development”,”salary”:6500})
db.emp.insert({_id:6,”ename”:”marry”,”age”:23,”department”:”Planning”,”salary”:5000})
db.emp.insert({_id:7,”ename”:”hellen”,”age”:32,”department”:”HR”,”salary”:6000})
db.emp.insert({_id:8,”ename”:”sarah”,”age”:24,”department”:”Development”,”salary”:7000})
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | > use company switched to db company > db.emp.aggregate( ... {$group:{_id: "$department" ,dpct:{$sum: 1 }}} ... ) { "_id" : "Development" , "dpct" : 3 } { "_id" : "HR" , "dpct" : 2 } { "_id" : "Planning" , "dpct" : 1 } { "_id" : "Sales" , "dpct" : 2 } > db.emp.aggregate( ... {$group:{_id: "$department" ,salct:{$sum: "$salary" },salavg:{$avg: "$salary" }}} ... ) { "_id" : "Development" , "salct" : 21500 , "salavg" : 7166.666666666667 } { "_id" : "HR" , "salct" : 10500 , "salavg" : 5250 } { "_id" : "Planning" , "salct" : 5000 , "salavg" : 5000 } { "_id" : "Sales" , "salct" : 14000 , "salavg" : 7000 } > db.emp.aggregate( ... {$match:{age:{$lt: 25 }}} ... ) { "_id" : 2 , "ename" : "eric" , "age" : 24 , "department" : "HR" , "salary" : 4500 } { "_id" : 5 , "ename" : "Mark" , "age" : 22 , "department" : "Development" , "salary" : 6500 } { "_id" : 6 , "ename" : "marry" , "age" : 23 , "department" : "Planning" , "salary" : 5000 } { "_id" : 8 , "ename" : "sarah" , "age" : 24 , "department" : "Development" , "salary" : 7000 } > db.emp.aggregate( ... {$match:{age:{$gt: 25 }}}, ... {$group:{_id: "$department" ,salct:{$sum: "$salary" },salavg:{$avg: "$salary" }}} ... ) { "_id" : "HR" , "salct" : 6000 , "salavg" : 6000 } { "_id" : "Development" , "salct" : 8000 , "salavg" : 8000 } { "_id" : "Sales" , "salct" : 8000 , "salavg" : 8000 } > db.emp.aggregate( ... {$group:{_id: "$department" ,salct:{$sum: "$salary" },salavg:{$avg: "$salary" }}}, ... {$match:{salavg:{$gt: 6000 }}} ... ) { "_id" : "Development" , "salct" : 21500 , "salavg" : 7166.666666666667 } { "_id" : "Sales" , "salct" : 14000 , "salavg" : 7000 } > > db.emp.aggregate( ... {$sort:{age: 1 }},{$limit: 3 } ... ) { "_id" : 5 , "ename" : "Mark" , "age" : 22 , "department" : "Development" , "salary" : 6500 } { "_id" : 6 , "ename" : "marry" , "age" : 23 , "department" : "Planning" , "salary" : 5000 } { "_id" : 2 , "ename" : "eric" , "age" : 24 , "department" : "HR" , "salary" : 4500 } > db.emp.aggregate( {$sort:{age:- 1 }},{$limit: 3 } ) { "_id" : 7 , "ename" : "hellen" , "age" : 32 , "department" : "HR" , "salary" : 6000 } { "_id" : 3 , "ename" : "robin" , "age" : 30 , "department" : "Sales" , "salary" : 8000 } { "_id" : 4 , "ename" : "jack" , "age" : 28 , "department" : "Development" , "salary" : 8000 } > db.emp.aggregate( {$sort:{age:- 1 }},{$skip: 4 } ) { "_id" : 2 , "ename" : "eric" , "age" : 24 , "department" : "HR" , "salary" : 4500 } { "_id" : 8 , "ename" : "sarah" , "age" : 24 , "department" : "Development" , "salary" : 7000 } { "_id" : 6 , "ename" : "marry" , "age" : 23 , "department" : "Planning" , "salary" : 5000 } { "_id" : 5 , "ename" : "Mark" , "age" : 22 , "department" : "Development" , "salary" : 6500 } > > db.emp.aggregate( {$project:{ "姓名" : "$ename" , "年龄" : "$age" , "部门" : "$department" , "工资" : "$salary" ,_id: 0 }}) { "姓名" : "tom" , "年龄" : 25 , "部门" : "Sales" , "工资" : 6000 } { "姓名" : "eric" , "年龄" : 24 , "部门" : "HR" , "工资" : 4500 } { "姓名" : "robin" , "年龄" : 30 , "部门" : "Sales" , "工资" : 8000 } { "姓名" : "jack" , "年龄" : 28 , "部门" : "Development" , "工资" : 8000 } { "姓名" : "Mark" , "年龄" : 22 , "部门" : "Development" , "工资" : 6500 } { "姓名" : "marry" , "年龄" : 23 , "部门" : "Planning" , "工资" : 5000 } { "姓名" : "hellen" , "年龄" : 32 , "部门" : "HR" , "工资" : 6000 } { "姓名" : "sarah" , "年龄" : 24 , "部门" : "Development" , "工资" : 7000 } > db.emp.aggregate( {$project:{ "姓名" : "$ename" , "年龄" : "$age" , "部门" : "$department" , "工资" : "$salary" ,_id: 0 }},{$match:{ "工资" :{$gt: 6000 }}}) { "姓名" : "robin" , "年龄" : 30 , "部门" : "Sales" , "工资" : 8000 } { "姓名" : "jack" , "年龄" : 28 , "部门" : "Development" , "工资" : 8000 } { "姓名" : "Mark" , "年龄" : 22 , "部门" : "Development" , "工资" : 6500 } { "姓名" : "sarah" , "年龄" : 24 , "部门" : "Development" , "工资" : 7000 } > |
Map Reduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)
MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
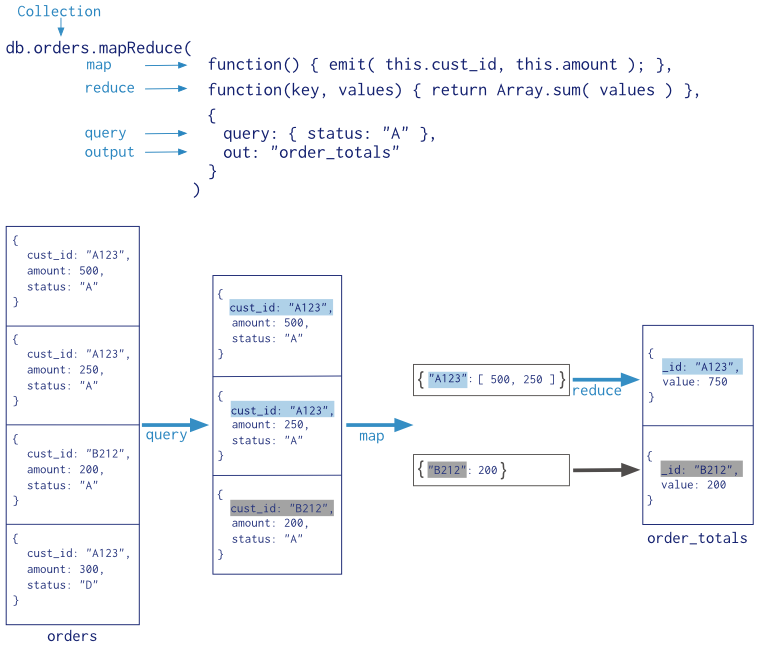
以下是MapReduce的基本语法:
>db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将key 与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | > db.emp.mapReduce( function () { emit( this .department, 1 ); }, function (key,values) { return Array .sum(values) }, { out: "depart_summary" } ).find() { "_id" : "Development" , "value" : 3 } { "_id" : "HR" , "value" : 2 } { "_id" : "Planning" , "value" : 1 } { "_id" : "Sales" , "value" : 2 } 利用内置的sum函数返回每个部门的人数 > db.emp.mapReduce( function () { emit( this .department, this .salary); }, function (key,values) { return Array .avg(values) }, { out: "depart_summary" } ).find() { "_id" : "Development" , "value" : 7166.666666666667 } { "_id" : "HR" , "value" : 5250 } { "_id" : "Planning" , "value" : 5000 } { "_id" : "Sales" , "value" : 7000 } 利用内置的avg函数返回每个部门的工资平均数 > db.emp.mapReduce( function () { emit( this .department, this .salary); }, function (key,values) { return Array .avg(values).toFixed( 2 ) }, { out: "depart_summary" } ).find() { "_id" : "Development" , "value" : "7166.67" } { "_id" : "HR" , "value" : "5250.00" } { "_id" : "Planning" , "value" : 5000 } { "_id" : "Sales" , "value" : "7000.00" } > 保留两位小数 > db.emp.mapReduce( function () { emit( this .department, this .salary); }, function (key,values) { return Array .sum(values) }, { out: "depart_summary" } ).find() { "_id" : "Development" , "value" : 21500 } { "_id" : "HR" , "value" : 10500 } { "_id" : "Planning" , "value" : 5000 } { "_id" : "Sales" , "value" : 14000 } > 利用内置的sum函数返回每个部门的工资总和 > db.emp.mapReduce( function () { emit( this .department,{count: 1 }); }, function (key,values) { var sum= 0 ; values.forEach( function (val){sum+=val.count}); return sum; }, { out: "depart_summary" } ).find() { "_id" : "Development" , "value" : 3 } { "_id" : "HR" , "value" : 2 } { "_id" : "Planning" , "value" : { "count" : 1 } } { "_id" : "Sales" , "value" : 2 } > 手工计算每个部门的员工总数 > db.emp.mapReduce( function () { emit( this .department,{salct: this .salary,count: 1 }); }, function (key,values) { var res={salct: 0 ,sum: 0 }; values.forEach( function (val){res.sum+=val.count;res.salct+=val.salct}); return res; }, { out: "depart_summary" } ).find() { "_id" : "Development" , "value" : { "salct" : 21500 , "sum" : 3 } } { "_id" : "HR" , "value" : { "salct" : 10500 , "sum" : 2 } } { "_id" : "Planning" , "value" : { "salct" : 5000 , "count" : 1 } } { "_id" : "Sales" , "value" : { "salct" : 14000 , "sum" : 2 } } > 手工计算每个部门的员工总数和工资总数 > db.emp.mapReduce( function () { emit( this .department,{salct: this .salary,count: 1 }); }, function (key,values) { var res={salct: 0 ,sum: 0 }; values.forEach( function (val){res.sum+=val.count;res.salct+=val.salct}); return res.salct/res.sum; }, { out: "depart_summary" } ).find() { "_id" : "Development" , "value" : 7166.666666666667 } { "_id" : "HR" , "value" : 5250 } { "_id" : "Planning" , "value" : { "salct" : 5000 , "count" : 1 } } { "_id" : "Sales" , "value" : 7000 } > 手工计算每个部门的工资平均值 > db.emp.mapReduce( function () { emit( this .department, this .salary); }, function (key,values) { return Array .avg(values) }, { out: "depart_summary" } ).find({value:{$gt: 5000 }}) { "_id" : "Development" , "value" : 7166.666666666667 } { "_id" : "HR" , "value" : 5250 } { "_id" : "Sales" , "value" : 7000 } 将分组计算后的值进行过滤显示,只显示工资平均数大于 5000 的部门 > db.emp.mapReduce( function () { emit( this .department, this .salary); }, function (key,values) { return Array .avg(values) }, { out: "depart_summary" } ).find({value:{$gt: 5000 }}).sort({value: 1 }) { "_id" : "HR" , "value" : 5250 } { "_id" : "Sales" , "value" : 7000 } { "_id" : "Development" , "value" : 7166.666666666667 } 将分组计算后的值进行排序,默认为升序 > db.emp.mapReduce( function () { emit( this .department, this .salary); }, function (key,values) { return Array .avg(values) }, { out: "depart_summary" } ).find({value:{$gt: 5000 }}).sort({value:- 1 }) { "_id" : "Development" , "value" : 7166.666666666667 } { "_id" : "Sales" , "value" : 7000 } { "_id" : "HR" , "value" : 5250 } > 将分组计算后的值进行排序,手工指定降序 > db.emp.mapReduce( function () { emit( this .department, this .salary); }, function (key,values) { return Array .avg(values) }, { out: "depart_summary" } ).find({value:{$gt: 5000 }}).sort({value:- 1 }).limit( 2 ) { "_id" : "Development" , "value" : 7166.666666666667 } { "_id" : "Sales" , "value" : 7000 } > 将分组计算后的值进行降序排序后,取其中的两个值 > db.emp.mapReduce( function () { emit( this .department,{count: 1 }); }, function (key,values) { var sum= 0 ; values.forEach( function (val){sum+=val.count}); return sum; }, { out: "depart_summary" ,query:{age:{$gt: 25 }} } ).find() { "_id" : "Development" , "value" : { "count" : 1 } } { "_id" : "HR" , "value" : { "count" : 1 } } { "_id" : "Sales" , "value" : { "count" : 1 } } > 分组前过滤数据,然后再分组计算 > db.emp.mapReduce( function () { emit( this .department,{count: 1 }); }, function (key,values) { var sum= 0 ; values.forEach( function (val){sum+=val.count}); return sum; }, { out: "depart_summary" ,query:{age:{$gt: 22 }},sort:{age: 1 } } ).find() { "_id" : "Development" , "value" : 2 } { "_id" : "HR" , "value" : 2 } { "_id" : "Planning" , "value" : { "count" : 1 } } { "_id" : "Sales" , "value" : 2 } > 分组前过滤数据,并排序,然后再分组计算 (本示例无意义) |
Group
基本语法如下:
db.runCommand({group:{
ns:集合名称,
key:分组的键对象,
initial:初始化累加器,
$reduce:组分解器,
condition:条件,
finalize:组完成器}})
分组首先会按照key进行分组,每组的每个文档全要执行$reduce方法,该方法接收2 个参数:一个是组内本条记录,一个是累加器数据
实例:
按照部门分组,计算每个部门的工资总和,如下所示:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 | > db.runCommand( ... {group:{ns: "emp" ,key:{ "department" : true },initial:{salct: 0 }, ... $reduce: function (oriDoc,prev){ prev.salct+=oriDoc.salary} ... }} ... ) { "waitedMS" : NumberLong( 0 ), "retval" : [ { "department" : "Sales" , "salct" : 14000 }, { "department" : "HR" , "salct" : 10500 }, { "department" : "Development" , "salct" : 21500 }, { "department" : "Planning" , "salct" : 5000 } ], "count" : NumberLong( 8 ), "keys" : NumberLong( 4 ), "ok" : 1 } > 统计每个部门的员工总量和工资总和,如下所示: > db.runCommand( {group:{ns: "emp" ,key:{ "department" : true },initial:{salct: 0 ,count: 0 }, $reduce: function (oriDoc,prev){ prev.salct+=oriDoc.salary;prev.count+= 1 } }} ) { "waitedMS" : NumberLong( 0 ), "retval" : [ { "department" : "Sales" , "salct" : 14000 , "count" : 2 }, { "department" : "HR" , "salct" : 10500 , "count" : 2 }, { "department" : "Development" , "salct" : 21500 , "count" : 3 }, { "department" : "Planning" , "salct" : 5000 , "count" : 1 } ], "count" : NumberLong( 8 ), "keys" : NumberLong( 4 ), "ok" : 1 } > 统计每个部门的员工总量、工资总和及平均值,如下所示: > db.runCommand( {group:{ns: "emp" ,key:{ "department" : true },initial:{salct: 0 ,count: 0 ,avg: 0 }, $reduce: function (oriDoc,prev){ prev.salct+=oriDoc.salary;prev.count+= 1 ; prev.avg=(prev.salct/prev.count).toFixed( 2 ) } }} ) { "waitedMS" : NumberLong( 0 ), "retval" : [ { "department" : "Sales" , "salct" : 14000 , "count" : 2 , "avg" : "7000.00" }, { "department" : "HR" , "salct" : 10500 , "count" : 2 , "avg" : "5250.00" }, { "department" : "Development" , "salct" : 21500 , "count" : 3 , "avg" : "7166.67" }, { "department" : "Planning" , "salct" : 5000 , "count" : 1 , "avg" : "5000.00" } ], "count" : NumberLong( 8 ), "keys" : NumberLong( 4 ), "ok" : 1 } > 统计每个部门的最高工资是多少,如下所示: > db.runCommand( {group:{ns: "emp" ,key:{ "department" : true },initial:{salct: 0 }, $reduce: function (oriDoc,prev){ if (oriDoc.salary>prev.salct){prev.salct=oriDoc.salary}} }} ) { "waitedMS" : NumberLong( 0 ), "retval" : [ { "department" : "Sales" , "salct" : 8000 }, { "department" : "HR" , "salct" : 6000 }, { "department" : "Development" , "salct" : 8000 }, { "department" : "Planning" , "salct" : 5000 } ], "count" : NumberLong( 8 ), "keys" : NumberLong( 4 ), "ok" : 1 } > 统计每个部门的最高工资,并对结果过滤,只显示大于 5000 的部门,如下所示: > db.runCommand( {group:{ns: "emp" ,key:{ "department" : true },initial:{salct: 0 }, $reduce: function (oriDoc,prev){ if (oriDoc.salary>prev.salct){prev.salct=oriDoc.salary}},condition:{salary:{$gt: 5000 }} }} ) { "waitedMS" : NumberLong( 0 ), "retval" : [ { "department" : "Sales" , "salct" : 8000 }, { "department" : "Development" , "salct" : 8000 }, { "department" : "HR" , "salct" : 6000 } ], "count" : NumberLong( 6 ), "keys" : NumberLong( 3 ), "ok" : 1 } > 将统计后的结果加上描述,如下所示: > db.runCommand( {group:{ns: "emp" ,key:{ "department" : true },initial:{salct: 0 }, ... $reduce: function (oriDoc,prev){ if (oriDoc.salary>prev.salct){prev.salct=oriDoc.salary}}, ... condition:{salary:{$gt: 5000 }}, ... finalize: function (prev){prev.salct= "Department of the highest salary is " +prev.salct} ... }}) { "waitedMS" : NumberLong( 0 ), "retval" : [ { "department" : "Sales" , "salct" : "Department of the highest salary is 8000" }, { "department" : "Development" , "salct" : "Department of the highest salary is 8000" }, { "department" : "HR" , "salct" : "Department of the highest salary is 6000" } ], "count" : NumberLong( 6 ), "keys" : NumberLong( 3 ), "ok" : 1 } > 用函数格式化分组的键:如果集合中出现键Department和department同时存在,那么分组有点麻烦,解决方法如下: > db.emp.insert({ ... "_id" : 9 , "ename" : "sophie" , "age" : 28 , "Department" : "HR" , "salary" : 18000 ... }) WriteResult({ "nInserted" : 1 }) > db.emp.find() { "_id" : 1 , "ename" : "tom" , "age" : 25 , "department" : "Sales" , "salary" : 6000 } { "_id" : 2 , "ename" : "eric" , "age" : 24 , "department" : "HR" , "salary" : 4500 } { "_id" : 3 , "ename" : "robin" , "age" : 30 , "department" : "Sales" , "salary" : 8000 } { "_id" : 4 , "ename" : "jack" , "age" : 28 , "department" : "Development" , "salary" : 8000 } { "_id" : 5 , "ename" : "Mark" , "age" : 22 , "department" : "Development" , "salary" : 6500 } { "_id" : 6 , "ename" : "marry" , "age" : 23 , "department" : "Planning" , "salary" : 5000 } { "_id" : 7 , "ename" : "hellen" , "age" : 32 , "department" : "HR" , "salary" : 6000 } { "_id" : 8 , "ename" : "sarah" , "age" : 24 , "department" : "Development" , "salary" : 7000 } { "_id" : 9 , "ename" : "sophie" , "age" : 28 , "Department" : "HR" , "salary" : 18000 } > > db.runCommand( {group:{ns: "emp" , ... $keyf: function (oriDoc){ if (oriDoc.Department){ return {department:oriDoc.Department}} else { return {department:oriDoc.department}}}, ... initial:{salct: 0 }, ... $reduce: function (oriDoc,prev){ if (oriDoc.salary>prev.salct){prev.salct=oriDoc.salary}}, ... condition:{salary:{$gt: 5000 }}, ... finalize: function (prev){prev.salct= "Department of the highest salary is " +prev.salct} ... }} ) { "waitedMS" : NumberLong( 0 ), "retval" : [ { "department" : "Sales" , "salct" : "Department of the highest salary is 8000" }, { "department" : "Development" , "salct" : "Department of the highest salary is 8000" }, { "department" : "HR" , "salct" : "Department of the highest salary is 18000" } ], "count" : NumberLong( 7 ), "keys" : NumberLong( 3 ), "ok" : 1 } > |
本文转自 meteor_hy 51CTO博客,原文链接:http://blog.51cto.com/caiyuanji/1836526,如需转载请自行联系原作者