什么是二叉查找树
wiki:https://en.wikipedia.org/wiki/Binary_search_tree
首先是名称:二叉查找树英文叫Binary search tree,这个在很多算法题目中很常见所以要记住,特别是英文题目中。也叫做二叉排序树,二叉搜索树等等。
具体的定义比较官方,用自己的话说,首先它肯定是二叉树,其次,当前节点的左子叶元素值比当前节点小,右子叶元素值比当前节点大,所以节点均满足这个规则的二叉树。

wiki中简介中简单描述了它的作用,用于根据键来快速的查询元素。
比如根据名字查询手机号。也给出了它的重要特点,查询,删除,新增速度快。
better than the linear time比线性的未排序的数组快;
slower than the corresponding operations on hash tables.比哈希表慢。
时间复杂度和空间复杂度
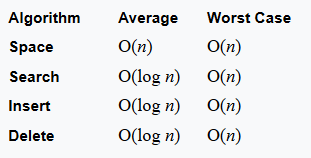
可以看到,平均为logN比N快。
其实也很好理解,因为二叉查找树的主要思想就是利用了二分查找的思想。每次查找都让一些不需要被遍历到的元素给移出了。而因为其特殊的数据结构存放方式,使得这样查找特别方便。
二叉查找树的操作
查找的过程就不赘述了,就是比较之后查左边还是查右边。实现很简单。也就不多说了。
对于第一次接触的人来说,主要的难点在于:
1、删除,很多人应该和我一样,对于树的删除节点一直很头疼总觉的一个不好整个树的结构就要变了。
2、新增,如果是新增最后的节点还好,但是新增中间的节点和删除一样生疼。
3、生成,说了半天,我们都是拿一颗已有的树来说话,但是对于大多数的题目来说,都需要你自己生成一颗树,那么如何生成呢?
删除
首先要把删除分成三种情况来讨论
第一种,最简单,如果要删除的节点没有子节点,那么就直接删除。
第二种,也简单,如果要删除的节点只有一个子节点,那么用这个子节点直接代替这个需要删除的节点即可。
第三种,麻烦一些,但是说简单也简单,注意理解!
首先你这样想,第三种情况是两边都有子节点,你删除这个节点必须要有一个元素代替这个位置,让整棵树不变才可以;我们继续想,如果一个排序好的列表,12345,如果要删除3这个元素,那么我们合理的想到就是拿2或者4代替它就可以了;也就是说,我们要在这棵树找到和删除元素相差最小的元素和它替换就可以了,这个数比它大,比它小都可以。
首先我们找比这个数小一个头的数;由二叉查找树的特性我们很简单就能找到它,我们先把需要删除的节点定为P,因为要找比P小的,那么我们先往左边找,左边都是比P小的,比P小的中最大的一个就是我们要找的,所以我们之后一直往右找,就找到了这个元素W,将这个元素和P替换,之后按照前面两种方法删除W就可以了,因为W元素肯定最多只有左子叶了。
下面用图来解释:
原来的树长这样

我们要删除7这个点,那么我们按照刚才说的,我们找左边最大的6
然后拿6替换7

然后按照前面两种方法,旧的6节点,前面的第二种方法说道,如果有一个。。。就。。。我不多说了,反正最后就这样了。

同理找8替换7也是一个意思,也是一种方法。
贴一下最后的结果,其实很简单。

所以,仔细理解一下,其实自己也能想到(滑稽脸)
删除的代码实现
//从二叉查找树中删除指针p所指向的结点 ,p非空,删除前驱方式 void removeNode1(BSTNode *& p) { BSTNode *q = NULL; if(!p->rchild)//*p的右子树为空 { q = p; p = p->lchild; delete q; } else if(!p->lchild)//*p的左子树为空 { q = p; p = p->rchild; delete q; } else//左右子树均不空 { BSTNode *s = NULL; q = p; s = p->lchild; //左子树根结点 while(s->rchild) //寻找结点*p的中序前驱结点, { //也就是以p->lchild为根结点的子树中最右的结点 q = s; //*s指向*p的中序前驱 s = s->rchild; //*q指向*s的父节点 } p->data = s->data; //*s结点中的数据转移到*p结点,然后删除*s if(q != p) //p->lchild右子树非空 { q->rchild = s->lchild;//把*s的左子树接到*q的右子树上 } else //p->lchild右子树为空 ,此时q ==p { q->lchild = s->lchild;//把*s的左子树接到*q的左子树上 } delete s; //删除结点*s } }
新增
首先,新增要满足一个条件,查找二叉树是不能有重复的两个元素的。
所以插入的元素不能已经存在于查找二叉树中。
然后纠正一个观点,插入的节点我们都把它放在最后的子叶节点中,而不会中间去插入。所以不用担心咯。
首先查找新增元素应该在的位置,查找我就不多说了,很简单的,如果这个元素存在就不加了,如果不存在,就加在那个位置就行了。
用图来说明,刚才我们删了7,那么我们再来加入7,最后成这样。

生成
说到这里,也就引出了我们最后一个,生成树。
为什么放在最后说呢?
其实明白人已经从前面的新增体会到了。
二叉查找树的样子千变万化,一颗树长成什么样子都可以。只要满足定义就可以了。
根据题目的意思去生成你需要的就可以了,题目肯定会给出一组乱序的树,你慢慢插入即可。