xl_echo编辑整理,欢迎转载,转载请声明文章来源。欢迎添加echo微信(微信号:t2421499075)交流学习。 百战不败,依不自称常胜,百败不颓,依能奋力前行。——这才是真正的堪称强大!! — ##### 阅读建议:如果系统没有做过相关导入导出,又需要这个量级的可以直接阅读底部的poi-ooxm的应用 > excel使用poi直接导出最大值是多少?估计很多人不会关注这个问题,因为很少有业务要求excel直接导出上万条数据,更甚者可能没有听过excel直接导出100w条数据。这里给大家介绍一个引用场景和博主采坑的经历。 #### 需求描述 公司要求实现一个银行流水的导出功能,看上去就是一个简单的按钮,但是这个需求有几点要求: – 导出的文件格式需要为xlsx – 每次导出最低量为5w条,且为一个表 – 导出的时候需要以文件下载的形式在浏览器下载 > 楼主开发环境:jdk1.8, idea2018.1,springboot1.5x,dubbox #### 对于poi-3.9的一次尝试 刚开始的时候,没有过多的关注5w条这个数量,直接使用的poi-3.9。在整个开发过程中基本没有碰到问题。在测试的时候,碰到了一个不能满足需求的问题。当我直接下载5w条的时候,程序直接报错。经过不断的测试,发现3.9的直接使用,最高下载值为6000+(这个最高值和电脑性能有一定的关系,不过出入不会很大)。 ###### 测试结论poi-3.9的天花板 6000+ > 很明显上面的尝试不能做出与需求相关的功能,经过百度,发现easyexcel是一个不错的解决方案。 #### 对于easyexcel的一次尝试 导入的easyexcel为 “`xml com.alibaba easyexcel 1.1.1 “` 使用该依赖的时候,我参考了以为博主的代码,代码地址为:https://blog.csdn.net/qq_35206261/article/details/88579151。当我将他的百万行级别的解决方案搬到我的项目中的时候,发现一切好像没有问题。但是当我启动的时候发现一直报错java.lang.NoSuchMethodError: org.apache.poi.ss.usermodel.Font.setBold(Z)V。(这里的错误来源于公司项目原有的项目导入依赖冲突,如果没有做过导入导出相关功能的应该不会出现)。经过排查发现,问题出现在依赖上面。公司原本是有导入和导出功能的 引入的依赖如下: “`xml org.apache.poi poi-ooxml 3.9 “` 冲突如下图所示: 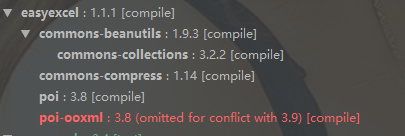 ##### 坑一poi-ooxml没有向下兼容 点击进入easyexcel的依赖发现,它的底层是依赖的poi3.17的版本。当我一直以为poi是能够向下兼容的时候,最终每次启动和编译的时候出现的问题都指向了并没有向下兼容。 底层的poi-ooxml版本为3.17,如图所示  这个时候我们可以如果还要去使用easyexcel,那我们需要更改版本或者解决poi-ooxml的版本兼容问题。 > 经过不兼容问题之后,看公司原有poi-ooxml的应用于是决定使用poi-ooxml的解决方案。 #### poi-ooxml的应用 经过以上几个坑之后,于是决定使用poi-ooxml的3.9版本能够兼容的解决方案,百度之后发现有一个以3.8版本基础的应用。经过上面的不兼容之后,还是决定试一试。于是采用了该博主文章中的一段代码,文章地址:https://blog.csdn.net/happyljw/article/details/52809244。 这篇文章中描述了一个思路,同时也给出了一段博主提供的实现代码,相对来说,如果作为测试问题不大,最后根据需求进行调整,修改了部分实现的步骤,同时也新增了一些新的实现和限制。代码如下: “`java @ResponseBody @RequestMapping(value = “/exportDataMoreThan1000”) public void readMoreThan1000RowBySheet(@RequestParam(value = “start”) Integer start, @RequestParam(value = “limit”) Integer limit, HttpServletResponse response) throws Exception { //内存中只创建100个对象,写临时文件,当超过100条,就将内存中不用的对象释放。 Workbook wb = new SXSSFWorkbook(100); //工作表对象 final Sheet[] sheet = {null}; //行对象 final Row[] nRow = {null}; //列对象 final Cell[] nCell = {null}; //总行号 final int[] rowNo = {0}; //页行号 final int[] pageRowNo = {0}; List list = new ArrayList<>(50000); //数据源 list = BankServer.getList(); list.forEach(it -> { if (rowNo[0] % 10001 == 0) { sheet[0] = wb.createSheet(“我的第” + (rowNo[0] / 10001 + 1) + “个工作簿”); sheet[0] = wb.getSheetAt(rowNo[0] / 10001); //每当新建了工作表就将当前工作表的行号重置为0 pageRowNo[0] = 0; } rowNo[0]++; nRow[0] = sheet[0].createRow(pageRowNo[0]++); //这一步很关键,如果没有就没有表头。 if (pageRowNo[0] == 1) { for (int j = 0; j < 9; j++) { nCell[0] = nRow[0].createCell(j); if (j == 0) nCell[0].setCellValue(“编号”); if (j == 1) nCell[0].setCellValue(“编号”); if (j == 2) nCell[0].setCellValue(“编号”); if (j == 3) nCell[0].setCellValue(“编号”); if (j == 4) nCell[0].setCellValue(“编号”); if (j == 5) nCell[0].setCellValue(“编号”); if (j == 6) nCell[0].setCellValue(“编号”); if (j == 7) nCell[0].setCellValue(“编号”); if (j == 8) nCell[0].setCellValue(“备注”); } rowNo[0]++; nRow[0] = sheet[0].createRow(pageRowNo[0]++); } // 输出每行,每行有9列数据 for (int j = 0; j < 9; j++) { nCell[0] = nRow[0].createCell(j); if (j == 0) nCell[0].setCellValue(it.getPaycode()); if (j == 1) nCell[0].setCellValue(it.getPaycode()); if (j == 2) nCell[0].setCellValue(it.getPaycode()); if (j == 3) nCell[0].setCellValue(it.getPaycode()); if (j == 4) nCell[0].setCellValue(it.getPaycode()); if (j == 5) nCell[0].setCellValue(it.getPaycode()); if (j == 6) nCell[0].setCellValue(it.getPaycode()); if (j == 7) nCell[0].setCellValue(it.getPaycode()); if (j == 8) nCell[0].setCellValue(it.getRemark()); } }); String fileName = “银行流水表.xlsx”; //设置请求头 response.setHeader(“content-Type”, “application/vnd.ms-excel”); response.setContentType(“application/vnd.ms-excel;charset=utf-8”); response.setHeader(“Content-Disposition”, “attachment; filename=” + fileName + “.xlsx”); ServletOutputStream outputStream = response.getOutputStream(); wb.write(outputStream); outputStream.flush(); outputStream.close(); } “` 这里简化了数据源的操作,如果需要可以根据自己的业务进行修改,我的实际实现里对数据源操作相对复查,不仅进行了分片请求(避免dubbox超时),同时还对数据进行了很多处理。这里的操作有一个亮点,那就是进行了多Sheet的分割。 ##### 注意:这里的开发环境是jdk1.8 当完成以上的代码编写之后,使用工具测试,发现已经实现了我需要的功能。目前的一个下载量10w以内都没有什么太大的问题,实测10w数据20s。如果业务逻辑简单些还会提升一倍的速度。 #### 总结: – 万行级的解决方案有两种 – * poi-ooxml – * easyexc – 如果使用其中的某一种要注意是否引入了另外一种,可能会不兼容。 – poi-ooxml3.9和poi-ooxml3.17不能完美向下兼容 – poi3.17最大下载峰值6000+