| rank | vote | view | answer | url |
|---|---|---|---|---|
| 97 | 974 | 754731 | 17 | url |
如何使用线程
这个是2010年提的问题了,这有一种使用 map 和 pool 的方法来使用线程.
下面的代码总结自 Parallelism in one line: A Better Model for Day to Day Threading Tasks,仅仅使用了几行代码:
from multiprocessing.dummy import Pool as ThreadPool
pool = ThreadPool(4)
results = pool.map(my_function, my_array)
使用 multithreaded 的版本:
results = []
for item in my_array:
results.append(my_function(item))
解释
Map 是一个非常 cool 的函数,它可以轻易地使你地 Python 代码实现并行.Map 是从像 Lisp 这种函数式语言学来的.它地作用是对序列中的每个元素进行函数的调用. Map 将迭代序列上所有的元素并且调用函数,最后将结果存储到列表中.
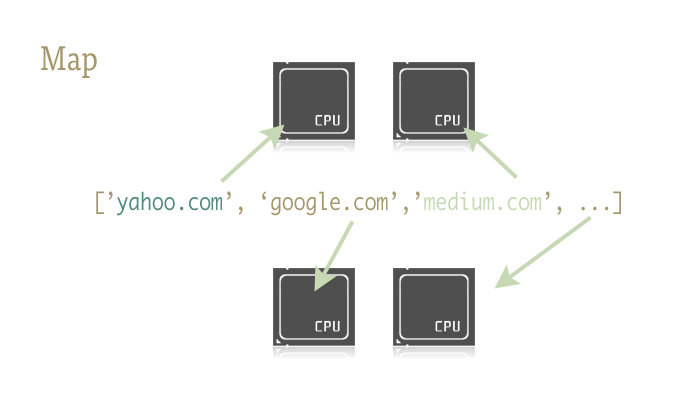
实现
并行版本的 Map 需要两个库来实现: multiprocessing 和 很少人知道地 multiprocessing.dummy.
multiprocessing.dummy 和 multiprocessing 模块很像, 但是使用线程进行替代(很重要的区别,进程处理 CPU 密集型作业, 而线程处理 IO 密集型作业):
multiprocessing.dummy实现了和 multiprocessing 一样当 API 但是内部使用的是 线程模块
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
]
# make the Pool of workers
pool = ThreadPool(4)
# open the urls in their own threads
# and return the results
results = pool.map(urllib2.urlopen, urls)
# close the pool and wait for the work to finish
pool.close()
pool.join()
结果如下:
Single thread: 14.4 seconds
4 Pool: 3.1 seconds
8 Pool: 1.4 seconds
13 Pool: 1.3 seconds
传入多个参数(像这样只在 Python3.3及更高版本生效)
传入多个数组:
results = pool.starmap(function, zip(list_a, list_b))
或者传递一个 constan 和数组:
results = pool.starmap(function, zip(itertools.repeat(constant), list_a))
如果使用老版本的 Python, 可以通过这个方法来实现