记得3年前还在上一家公司的时候, 一天下午一个哥们很激动的在偶旁边念叨”散列表真是个好东西,散列表真是个好东西….”绵绵不绝, 偶石化继而抓狂,奋起曰:”你复读机啊你复读机啊你复读机啊…”.
散列表不是复读机, 散列表更像是一个大池子(但是不是所有的大池子都可以认为是散列表). 这个特殊的大池子有这样的特点, 它的容量总是要比你想要存储的元素数量大, 它能利用大出一部分容量的特点, 让你能更加快速的查找定位某一元素.
牺牲一点点内存,换取更高效的表现, 有人问值不值得? 大哥,现在1G的内存都100多块钱了…
第一部分: 散列表的基本知识
散列表是这样一种数据结构: 它利用散列函数(通常称为函数h(k))计算元素关键字(标记k)的散列值, 并根据该散列值, 直接确定(或者通过简单数学计算)该元素在散列表中的存储位置(散列表中的存储位置我们称为槽Slot). 如果两个元素关键字通过散列函数的计算获得了同样的散列值, 从而指向散列表中的同一个槽, 我们称这种现象为”碰撞(Collision)”.由于元素关键字域U的容量大于散列表T的容量m, 所以完全避免碰撞是不可能的. 这就引申出了散列表最为重要的两个问题:
- 如何最大可能的减少碰撞? – 选择好的散列函数
- 发生碰撞以后应该怎么办? – 碰撞解决技术
- 1. 选择好的散列函数
散列函数优劣的评价标准是, 它能否将每个关键字独立地等可能地散列到散列表T的任何一个槽当中. 独立意味着每个元素的散列结果都不受其他元素的影响,等可能是说散列后,每个槽存储的元素数量尽可能均匀.
我们将现在常见的散列算法归类,可以归结为大概3类: 除法散列法, 乘法散列法, 全域散列.
实际上,我们在进行散列之前,要做点准备工作 – 将关键字解释为自然数. 比如字符串我们常按照它的ASCII码值解释等.这个算法你可以自己任意去玩, 不过我们知道C#默认的解释方法是Object.GetHashCode().你可以接受这个方法的默认实现,当然你如果觉得它不爽也可以重写它.前提是你的Object要实现IEqualityComparer接口.
好吧,现在开始, 由关键字获得的自然数我们用k来表示, 哈希表的容量我们用m来表示
除法散列法的散列函数是: h(k) = k mod m,算法相当简单因而也是最常用的算法. 唯一的问题在于m的选择(注意, 这里是根据想要存储的元素数量来决定散列表的容量m). 好吧, 选择m也有两个诀窍, 第一,不要选择2的幂(因为mod 2的幂相当于只根据元素的高位散列, 更加容易碰撞); 第二, 尽量选择比2的幂差得比较远的质数.例如C#的Hashtable的实现就是选择比元素数量大一点点的质数.
乘法散列法的散列函数是: h(k) = ∟m(kA mod 1) ∟,(请原谅我不知道怎么用Live Writer 打出求底符号) A是介于0和1之间的小数. kA mod 1 即 kA的小数部分, 一般选择m为2的幂. A值的选择, Kurth认为它最好的值是(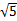 – 1)/2, 即大约0.618.
– 1)/2, 即大约0.618.
全域散列法用得很少,此处略过.
- 2.碰撞解决技术
在发生碰撞以后, 后来元素该怎么处理? 思路大概上就有了2种: 重新散列和链表保存.
先说链表保存. 散列表保存不再是元素本身, 而是元素的关键字值, 并且该关键字值结构作为一个链表头,指向一个链表,这个链表保存的元素其关键字值等于链表头里面的关键字值.
这种方法的插入过程是: 计算散列值 -> 找到链表头 -> 找到链表尾部 ->将元素连缀在尾部
这种方法的搜索过程是: 计算散列值 -> 找到链表头 -> 遍历链表
由此看出这种算法的时间复杂度主要由链表操作决定, 所以链表的长度, 或者精确地说, 链表的平均长度, 决定了这个算法的效率. 如果散列函数足够坏, 将所有的元素都散列到了一个链表中,那这种情况下就是最坏的时间复杂度, 为O(n), 而不是一般散列表所预期的O(1).
好吧,如果你愿意承受着个算法,那他给你带来的好处事你可以在散列表里面存储远远多于散列表槽数的元素, 即使那样的散列表已经没有了什么意义.
另外一种我们常见的碰撞解决技术就是开放开放寻址法了. 基本上, 它采用的事重新散列的思想.
当发生碰撞时, 新进入的元素标记碰撞次数并且按照散列函数(这个散列函数包含了对碰撞次数的计算)重新计算,获取新的散列值, 然后如果遇到新的碰撞, 重复执行这一过程,直到没有碰撞情况发生.
重新散列的方式, 根据散列函数的不同, 又大体分为3类: 线性散列, 二次散列, 双重散列.
线性散列主要强调的是线性步进, 这个步进可以由你控制, 比如1, 比如2, 比如4等.
二次散列主要强调的是探查按照某常数的二次方步进, 比如第一次是2, 第二次是4, 第三次是8….., 这种方法的效果要比线性探查好得多.
双重散列事开放寻址法的最好方法. 它的散列函数大体如下:
h(k,i) = ( h1(k) + i*h2(k) ) mod m, 其中 i是发生碰撞的次数, k是关键字值, m是散列表的容量, h1, h2是两个散列函数称为辅助散列函数,
为了能查找整个散列表, 值h2(k)要与表大小m互质!!! 一般设计为h2(k)是一个总是产生质数的函数, 或者m是一个质数并且h2总是产生比m小的正整数.比如, 我们可以去m为质数, h1(k) = k mod m, h2(k) = 1+ ( k mod (m-1) ) ——-m-1比m略小.
双重散列的探查序列是m的平方级别的, 而线性和二次都是m级别的, 因此双重散列的效果要好得多, 实际上, C#的Hashtable应用的就是双重散列, 下一篇blog我们研究一下C#的Hashtable的实现:)