哈弗曼树,在数据结构这门课中,已经学过,也叫做最优二叉树。
广泛的应用于数据文件压缩中。
根据百度百科给出基本术语
1、路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或子孙结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
2、结点的权及带权路径长度(码长)
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
3、树的带权路径长度(树的总码长)
树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
好了,下面就来回顾一下整个一个产生过程
在40年代,香农创立信息论(主要是为解决通讯编码问题而提出的),自然而然就涉及到一个数据压缩的问题,然后香农把熵的概念引入到信息论中来(熵表示一条信息中真正需要编码的信息量,原为热力学中的名词),具体如下(摘自http://bbs.chinaunix.net/thread-149731-1-1.html几种压缩算法一文)
考虑用 0 和 1 组成的二进制数码为含有 n 个符号的某条信息编码,假设符号 Fn 在整条信息中重复出现的概率为 Pn,则该符号的熵也即表示该符号所需的位数位为:
En = – log2( Pn )
整条信息的熵也即表示整条信息所需的位数为:E = ∑En
举个例子,对下面这条只出现了 a b c 三个字符的字符串:
aabbaccbaa
字符串长度为 10,字符 a b c 分别出现了 5 3 2 次,则 a b c 在信息中出现的概率分别为 0.5 0.3 0.2,他们的熵分别为:
Ea = -log2(0.5) = 1
Eb = -log2(0.3) = 1.737
Ec = -log2(0.2) = 2.322
整条信息的熵也即表达整个字符串需要的位数为:
E = Ea * 5 + Eb * 3 + Ec * 2 = 14.855 位
回想一下如果用计算机中常用的 ASCII 编码,表示上面的字符串我们需要整整 80 位!
用较少的位数表示较频繁出现的符号,这就是数据压缩的基本准则。
那下面就给出Shannon-Fano 编码的一个具体的例子
对下面这串出现了五种字符的信息( 40 个字符长 ):cabcedeacacdeddaaabaababaaabbacdebaceada
五种字符的出现次数分别:a – 16,b – 7,c – 6,d – 6,e – 5。
Shannon-Fano 编码的核心是构造二叉树,构造的方式如下:
1) 将给定符号按照其频率从大到小排序。对上面的例子,应该得到:
a – 16 b – 7 c – 6 d – 6 e – 5
2) 将序列分成上下两部分,使得上部频率总和尽可能接近下部频率总和。我们有:
a – 16
b – 7
—————–
c – 6
d – 6
e – 5
3) 我们把第二步中划分出的上部作为二叉树的左子树,记 0,下部作为二叉树的右子树,记 1。
4) 分别对左右子树重复 2 3 两步,直到所有的符号都成为二叉树的树叶为止。现在我们有如下的二叉树:
根(root)
0 | 1
+——+——+
0 | 1 0 | 1
+—–+—–+ +—+—-+
| | | |
a b c |
0 | 1
+—–+—–+
| |
d e
于是我们得到了此信息的编码表:
a – 00 b – 01 c – 10 d – 110 e – 111
可以将例子中的信息编码为:
cabcedeacacdeddaaabaababaaabbacdebaceada
10 00 01 10 111 110 111 00 10 00 10 ……
码长共 91 位。考虑用 ASCII 码表示上述信息需要 8 * 40 = 240 位,我们确实实现了数据压缩。
在1951年,霍夫曼和他在MIT信息论的同学需要选择是完成学期报告还是期末考试。导师Fano给他们的学期报告的题目是,寻找最有效的二进制编码。由于无法证明哪个已有编码是最有效的,霍夫曼放弃对已有编码的研究,转向新的探索,最终发现了基于有序频率二叉树编码的想法,并很快证明了这个方法是最有效的。
由于这个算法,学生终于青出于蓝,超过了他那曾经和信息论创立者克劳德·香农共同研究过类似编码的导师。霍夫曼使用自底向上的方法构建二叉树,避免了次优算法Shannon-Fano编码的最大弊端──自顶向下构建树。(摘自维基百科)
但是这个算法怎么产生的呢,霍夫曼也没有说清楚他当时怎么思考的,下面参考http://mindhacks.cn/2011/07/10/the-importance-of-knowing-why-part3/ 刘未鹏“知其所以然(三):为什么算法这么难?”一文。
对于算法问题有个一般性的思考过程
1、看一看解空间的构成
也就是首先先想一想这个问题我能不能给出一个解,或者看看能不能穷举所有的可能,这样有解的话,解就会在其中,不然就无解。
对于哈弗曼编码来说,这个编码树是有限的,我们列出所有的可能,然后找出总码长(树的带权路径长度)最小的。这样说应该会有解。
下一步我们就想怎么来提高这个效率呢。
2、我们自然想到的是如何排除一些不可能的条件。
这样要查找的范围就小了,但是怎么排除呢,根据已知的性质可能很难发现,那下一步就很重了。
3、这一步是很重要,采用数学中一个很重要的思想,倒推法
假设结论成立,把结论当作条件使用,将会得出什么性质,得出的这些性质就是结论(找到最优解)的必要条件。
那下面我们就假设我们已经得到了最优编码树,我们能够发现关于它的什么性质呢。
下面我们要明白这么一个概念,所谓的最优解也就是比其它解更好,也就是比与它相连的所有其它解都好,也就是我们在最优的解上做一个变化,得到的解就没有以前的解好。
这么我们假设树中的两个叶子节点的频率是f1和f2,深度是d1和d2,互换它们的时候,则其它节点的总码长为cost不变为C,则树的总cost为C+f1d1+f2d2,交换之后为C+f1d2+f2d1,则自然的C+f1d1+f2d2 < C+f1d2+f2d1,也就是f1(d1-d2)<f2(d1-d2),也就是说如果d1<d2则f1>f2,如果d1>d2则f1<f2,这样我们就得到,这个最优编码树满足深度越大,则频率就要越小,深度越小,频率就要越大。这样我们就很自然的得到频率越小的节点其就应该在树的最底层,频率高的节点就应该在树的最上层。有了这个结论之后,我们就会发现我们已经排除了很多的可能性。
在这之前我们也要明白一个概念就是前缀码的概念,就是对于数据压缩编码之后,我们要进行解码,这样的话,我们就要求任何一个字符的代码都不能是其他字符代码的前缀,而采用树的编码方式正好满足了这一点,树根到树叶(字符在叶子节点)的路径不可能是另外一个字符的前缀路径。
下面我们就构造树,怎么构造呢,下面就存在在这么一个问题,是一开始将频率低的两个节点作为兄弟节点,还是就是两个独立的节点呢。
4、这边采用了数学中另外一个思想——归约
我们就想不是兄弟的节点能不能归约到兄弟节点呢,我们假设如果不是兄弟节点,我们得到了最优解,那我们交换一下位置,让这两个节点成为兄弟节点,看看是不是还是最优解,这个结论是肯定的,C+f1d1+f2d2(d1=d2),则交换了,总码数不变,仍然是最优解。那这样的话我们就可以进行下一步构造,那下一步怎么构造了,又是个问题,虽然现在知道了,将最小频率的两个节点先构造成一棵树,下一步呢,是将另外两个节点也构造成一棵树,还是将先前构造的一棵树的基础上再次构造呢。
5、我们也很自然的想,这两个方式是不是一样的呢,这样我们很自然的就先举个例子。
看看是不是一样,还是哪个好,然后我们下一步在证明这个到底为什么好,这样就先给出两个图
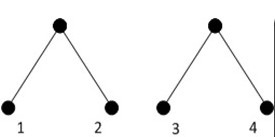
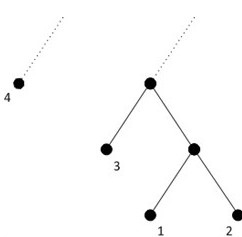
这就是两种构造方式,注意的是,这边的1,2,3,4不是节点的编号,而是节点的频率,这样就会发现以频率为3的节点为基准,则下图相比上图,1,2频率的点深度+1,4频率的点深度-1,这样总的频率是+3-4=-1变小了,这样下面的这一种才是我们应该要找的构造方式,这样我们分析为什么会是这个样子的呢,想到对于0,1编码来说,已经构造好的一颗子树来说它已经拥有了0,1这两种可能,这样着一颗树就已经可以是一个整体,这样这一个整体的频率之和也就是这两个节点的频率之和(相对高度为1),这样再将频率最小的两个节点合并,此时已经合并的作为一个整体。这样渐渐的就得出了哈弗曼树的一个构造过程。
好,这个构造过程是不错,但是我们怎么能说这个就是最优的编码树呢,这个是要证明的,也就是我们给出一个算法的话,我们是要对这个算法进行正确性的证明的。而对于一个算法的证明,我们也自然的想到通过算法证明最基本的思想,循环不定式。
也就是要证明它的三个性质:
初始化,保持,终止。其实这个也就跟数学中的归纳法很相似
也就是要证明一开始选择频率最低的两个节点构造树是存在最优前缀编码的
其次要证明的就是我去掉频率最低的两个节点,换成一个新的节点,此时得到的这个前缀编码仍然是一个最优的前缀编码。
最后再看看终止的情况。而对于这样的算法是不用说明终止情况,对于现在我们已经总结这个哈弗曼算法是一种贪心算法,对于贪心算法肯定有终止,要证明的就是这个问题具有贪心选择性和最优子结构性,而这两个性质其实就是循环不定式的前两个性质。其实也就是用类似于数学归纳法的思想来证明一下这个算法的正确性。
下面就用形象化的语言描述一下这个问题。
1、设C是编码字符集,C中字符c的频率为f (c) ,又设x和y是C中具有最小频率的两个字符,则在x和y最先构造时(在树的最底层)存在C的最优前缀编码。
2、去掉两个节点且为兄弟节点x,y,改为其父节点z,此时构造的前缀码树仍然最优前缀编码。
也就是要证明上面这两个问题即可,那怎么证明呢,(我们就想现在这两个字符的频率最小,如果在构造的最优编码树中这两个字符的深度也是最深的话,不就行了,)还是我们先假设已经存在了这个最优前缀编码,我们把构造好的这个二叉树修改一下,将x和y作为修改后得到的树的最深的节点并且为兄弟节点,而这两棵树的码长一样的话,这样我们不就得到了证明。(这种倒退的思想比较重要)
好的,下面的话,我们就先假设b和c是二叉树T的最深叶子节点,这样我们不妨设f(b)<=f(c),f(x)<=f(y),由于x和y是C中具有最小频率的两个字符,则有f(x)<=f(b),f(y)<=f(c),然后依次交换b和x节点,c和y节点,再计算,整个的一个计算思路上面已经给出,这边也就不再叙述。
下面也就是整个一个程序实现的过程,这个网上有很多的代码,这边我也要努力学习,对于一个数学问题,当给出其一个算法过程的时候,我们怎么很好的写出这个代码实现的过程,有的时候,我也想好好的学好数学,可惜的是自己没有这个心去坚持下来,数学是好好学的,尤其对于我们学计算机的来说,但是怎么去学好这个数学,学好了这个数学如何运用到我们这个计算机上,这个就是我们现在要考虑的事,加油。。。