全解排序算法
排序:就是重新排列表中的元素,是表中的元素满足按关键字递增或递减的过程。为了查找方便,通常要求计算机中的表是按关键字有序的。排序的确切定义如下:
输入:n个记录R1,R2, …,Rn对应的关键字为k1,k2,…,kn。
输出:输入序列的一个重排R1′,R2′, …,Rn’,使得有k1′<=k2′<=…<=kn’(其中“<=”办以换成其他的比较大小的符号)。
算法的稳定性:如果待排序表中有两个元素Ri、Rj,其对应的关键字keyi=keyj,且排序前Ri在Rj前面,如果使用某—排序算法排序后,Ri仍然在Rj前面,则称这个的,否则称排序算法是稳定的,否则称排序算法是不稳定的。需要注意的是,算法是否具有稳定性并不能衡量一个算法的优劣,它主要是对算法的性质进行描述。
注意:对于不稳定的排序算法,只需举出一组关键字的实例说明它的不稳定性即可。
在排序的过程中,根据数据元素是否完全在内存中,可将排序算法分为两类:内部排序是指在排序期间元素全部存放在内存中的排序;外部排序是指在排序期间元素无法全部同时存放在内存中,必须在排序的过程中根据要求不断地在内、外存之间移动的排序。
—般情况下,内部排序算法在执行过程中都要进行两种操作:比较和移动。通过比较两个关键字,确定对应的元素的前后关系,然后通过移动元素以达到有序。当然,并不是所有的内部排序算法都要基于比较操作,事实上,基数排序就不是基于比较的。
内部排序算法的性能取决于算法的时间复杂度和空间复杂度,而时间复杂度一般是由比较和移动的次数来决定的。

没有特别说明,本文默认为升序排序。
一.插入排序
插入排序是一种简单直观的排序方法,其基本思想在于每次将一个待排序的记录,按其关键字从小插入到前面已经排好序的子序列中,直到全部记录插入完成。
由插入排序的思想可以引出三个重要的排序算法:直接插入排序、折半插入排序、希尔排序。
1.直接插入排序
思想:
插入排序的基本操作是在一个有序表中进行查找和插入。先将序列的第1个记录看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。整个排序过程为进行 n-1 趟插入。
算法描述:
1)查找出L(i)在L[1…i-1]中的插入位置k。
2)将L[k…i-1]中所有元素全部后移一个位置。
3)将L(i)复制到L(k)。
例如,已知待排序的 一组记录的初始排 列如下所示:
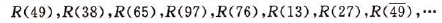 (1-1)
(1-1)
假设在排序过程中,前 4 个记录已按关键宇递增的次序重新排列,构成一个含4个记录的有序序列
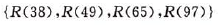 (1-2)
(1-2)
现要将式(1-1) 中第 5 个〈即关键字为 76 的〉记录插入上述序列,以得到一个新的含5 个记录的有序序列。
则首先要在式(1-2) 的序列中进行查找以确定 R(76)所应插入的位置,然后进行插入.
假设从 R(97) 起向左进行顺序查拢,由于 65<76<97,则 R(76)应插入在 R(65) 和 R(97) 之间,从而得到下列新的有序序列
{ R(38) ,R(49) ,R(6 日,R(76) ,R(97) } (1-3)
称从式(1-2) 到式(1-3)的过程为一趟直接插入排序.
一般情况下 ,第 i趟直接插入排序的操作为:在含有i-1 个记录的有序子序列 r[1..i-1]中插入一个记录 r[i]后 ,变成含有 4 个记录的有序子序列 r[1..i] ;并且,和顺序查找类似,为了在查找插入位置的过程中避免数组下标出界,在 r[0] 处设置监视哨。在自 i-1 起往前搜索的过程中,可以同时后移记录。整个排序过程为进行 n-1 趟插入,即:先将序列的第1个记录看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
注:
将r[0]设立监视哨,作为临时存储和判断数组边界之用(避免数组下标出界)。算法的书写都是以r[0]为监视哨(r[0]不存数据,实际应用中可用变量代替临时存储,但避免数组下标出界)。
示例:
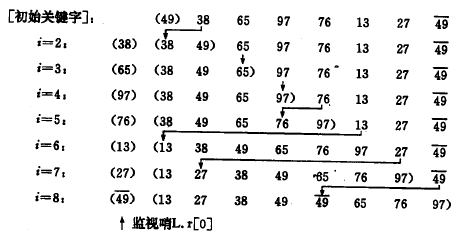
算法:
void InsertSort(ElemType A[] ,int n){ int i,j; for(i=2;i<=n;i++){ //依次将A[2]-A[n]插入到前面已排序序列 if(A[i].key<A[i-1].key){ //若A[i]的关键码小于其前驱,需将 A[i]插入有序表 A[0]=A[i]; //复制为哨兵 for(j=i-1;A[0].key<A[j].key;--j){//从后往前査找待插入位置 A[j+1]=A[j]; //向后挪位 } A[j+1]=A[0]; //复制到插入位置 } } }
性能分析:
空间效率:仅使用了常数个辅助单元,因而空间复杂度为O(1).
时间效率:在排序过程中,向有序子表中逐个地插入元素的操作进行了n-l趟,每趟操作都分为比较关键字和移动元素,而比较次数和移动次数取决于待排序的初始状态。在最好情况下,表中元素已经有序,此时每插入一个元素,都只需比较一次不用移动元素,因而时间复杂度为0(n)。
在最坏情况下,表中元素顺序刚好与排序结果中元素顺序相反(逆序)时,总的比较次数达到最大,为 ,总的移动次数也达到最大,为
,总的移动次数也达到最大,为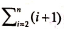 。
。
平均情况下,考虑待排序表中元素是随机的,此时可以取上述最好与最坏情况的平均值作为平均情况下的时间复杂度,总的比较次数与总的移动次数均约为。
由此,直接插入排序算法的时间复杂度为 虽然折半插入排序算法的时间复杂度也有
虽然折半插入排序算法的时间复杂度也有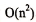 ,但对于数据量比较小的排序表,折半插入排序往往能表现出很好的性能。
,但对于数据量比较小的排序表,折半插入排序往往能表现出很好的性能。
稳定性:每次插入元素时总是从后向前先比较再移动,所以不会出现相同元素相对位置发生变化的情况,即直接插入排序是—个稳定的排序方法.
适用性:直接插入排序算法适用于顺序存储和链式存储的线性表。当为链式存储时,可以从前往后查找指定元素的位置。注意:大部分排序算法都仅适用于顺序存储的线性表。
2.折半插入排序
思想:
插入排序的基本操作是在一个有序表中进行查找和插入,注意到该算法中,总是边比较边移动元素,下面将比较和移动操作分离,先找出元素的待插入位置,再统一地移动待插入位置之后的所有元素。折半插入排序针对“查找”进行优化,主要减少关键字间的比较次数。
取有序表的中间节点,与r[0]比较,大于r[0]查找左半子表,小于r[0]查找右半子表;循环,直到low不小high。
算法:
void InsertSort(ElemType A[] ,int n){ int i,j,low,high,mid; for(i=2;i<=n;i++){ //依次将A[2]-A[n]插入到前面已排序序列 if(A[i].key<A[i-1].key){ //若A[i]的关键码小于其前驱,需将 A[i]插入有序表 A[0]=A[i]; //复制为哨兵 low=1;high=i-1; while(low<high){ mid=(low+high)/2; //取中间点 if(A[mid].key>A[0].key) high=mid-1; //查找左半子表 else low=mid+1; //查找右半子表 } for(j=i-1;A[0].key<A[j].key;--j){//从后往前査找待插入位置 A[j+1]=A[j]; //向后挪位 } A[j+1]=A[0]; //复制到插入位置 } } }
从上述算法中,不难看出折半插入排序仅仅是减少了比较元素的次数,约为 ,该比较次数与待排序表的初始状态无关,仅取决于表中的元素个数n;而元素的移动次数没有改变,它依赖于待排序表的初始状态。因此,折半插入排序的时间复杂度仍为
,该比较次数与待排序表的初始状态无关,仅取决于表中的元素个数n;而元素的移动次数没有改变,它依赖于待排序表的初始状态。因此,折半插入排序的时间复杂度仍为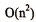 。折半插入排序是一个稳定的排序方法。
。折半插入排序是一个稳定的排序方法。
注:for循环
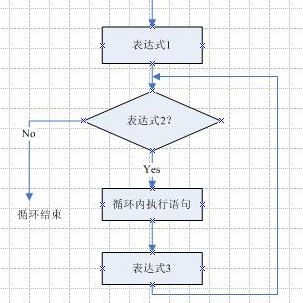
for循环形式: for(表达式1;表达式2;表达式3),流程图:
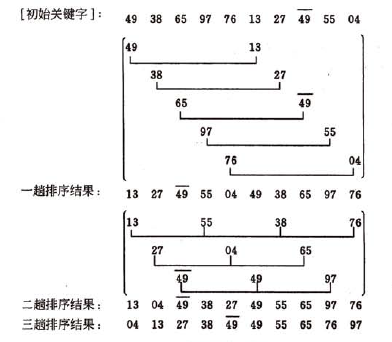
3.希尔排序
从前面的讲解不难看出,直接插入排序算法适用于基本有序的排序表和数据量不大的排序表。基于这两点,1959年D.L.Shell提出了希尔排序,又称为缩小增量排序。
思想:
先将待排序表分割成若干个形如L[i, i+d, i+2d,…i+kd]的“特殊”子表,分别进行直接插入排序,当整个表中元素已呈“基本有序”时,再对全体记录进行—次直接插入排序。
算法描述:
先取一个小于n的步长d1,把表中全部记录分成d1个组,所有距离为d1的倍数的记录放在同一个组中,在各组中进行直接插入排序;然后取第二个步长d2<d1,重复上述过程,直到所取到的dt=1,即所有记录已放在同—组中,再进行直接插入排序,由于此时已经具有较好的局部性,故可以很快得到最终结果。
增量序列的设置:
到目前为止,尚未求得一个最好的增量序列,希尔提出的方法是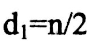 ,
,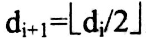 。
。
示例:
算法:
void ShellSort (ElemType A[],int n){ //对顺序表作希尔插入排序,本算法和直接插入排序相比,作了以下修改: //1.前后记录位置的增量是dk,不是1 //2.r[0]只是暂存单元,不是哨兵,当j<0时,插入位置已到 for (dk=len/2; dk>=l; dk=dk/2) //步长变化 for(i=dk+l;i<=n;++i) if (A[i].key<A[i-dk].key) { //需将A[i]插入有序增量子表 A[0]=A[i]; //暂存在 A[0] for(j=i-dk;j>0&&A[0].key<A[j].key;j-=dk) A[j+dk]=A[j]; //记录后移,查找插入的位置 A[j+dk]=A[0]; //插入 }//if }
性能分析:
空间效率:仅使用了常数个辅助单元,空间复杂度为0(1)。
时间效率:由于希尔排序的时间复杂度依赖于增量序列的函数,这涉及数学上尚未解决的难题,所以其时间复杂度分析比较困难。当n在某个特定范围时,希尔排序的时间复杂度约为0(n13)。在最坏情况下希尔排序的时间复杂度为0(n2)。
稳定性:当相同关键字的记录被划分到不同的子表时,可能会改变它们之间的相对次序, 因此,希尔排序是一个不稳定的排序方法。例如,表L={3, 2’, 2},经过一趟排序后,L={2, 2′, 3},最终排序序列也是L={2, 2′, 3},显然,2与2’的相对次序已经发生了变化。
适用性:希尔排序算法仅适用于当线性表为顺序表的情况。
————————————————————————————————————————————-
未完待续
转载需注明转载字样,标注原作者和原博文地址。